76: From C to Rust on Mobile
Meta Tech Podcast •

What happens when decades-old C code, powering billions of daily messages, starts to slow down innovation? In this episode, we talk to Meta engineers Elaine and Buping, who are in the midst of a bold, incremental rewrite of one of our core messaging libraries—in Rust. Neither came into the project as Rust experts, but both saw a chance to improve not just performance, but developer experience across the board.
We dig into the technical and human sides of the project: why they took it on, how they’re approaching it without a guaranteed finish line, and what it means to optimise for something as intangible (yet vital) as developer happiness. If you’ve ever wrestled with legacy code or wondered what it takes to modernise systems at massive scale, this one’s for you.
Got feedback? Send it to us on Threads (https://threads.net/@metatechpod), Instagram (https://instagram.com/metatechpod) and don’t forget to follow our host Pascal (https://mastodon.social/@passy, https://threads.net/@passy_). Fancy working with us? Check out https://www.metacareers.com/.
Timestamps
-
Intro 0:06
-
Introduction Elaine 1:54
-
Introduction Buping 2:49
-
Team mission 3:15
-
Scale of messaging at Meta 3:40
-
State of native code on Mobile 4:40
-
Why C, not C++? 7:13
-
Challenges of working with C 10:09
-
State of Rust on Mobile 18:10
-
Why choose Rust? 23:36
-
Prior Rust experience 28:55
-
Learning Rust at Meta 34:14
-
Challenges of the migration 37:47
-
Measuring success 42:09
-
Hobbies 45:15
-
Outro 46:41
AI hot takes and debates: Autonomy
Practical AI •

Can AI-driven autonomy reduce harm, or does it risk dehumanizing decision-making? In this “AI Hot Takes & Debates” series episode, Daniel and Chris dive deep into the ethical crossroads of AI, autonomy, and military applications. They trade perspectives on ethics, precision, responsibility, and whether machines should ever be trusted with life-or-death decisions. It’s a spirited back-and-forth that tackles the big questions behind real-world AI.
Featuring:
Links:
- The Concept of "The Human" in the Critique of Autonomous Weapons
- On the Pitfalls of Technophilic Reason: A Commentary on Kevin Jon Heller’s “The Concept of ‘the Human’ in the Critique of Autonomous Weapons”
Sponsors:
- Outshift by Cisco: AGNTCY is an open source collective building the Internet of Agents. It's a collaboration layer where AI agents can communicate, discover each other, and work across frameworks. For developers, this means standardized agent discovery tools, seamless protocols for inter-agent communication, and modular components to compose and scale multi-agent workflows.
Fri. 06/27 – The Death Of The Blue Screen Of Death
Techmeme Ride Home •

Mark Zuckerberg’s big AI plan seems still to be such a work in progress, he’s even considering abandoning Llama. Apple attempts to comply with the EU’s DMA. Instagram and TikTok want to follow YouTube to your TV. The infamous Blue Screen of Death is dying. And, of course, the Weekend Longreads Suggestions.
Links:
- In Pursuit of Godlike Technology, Mark Zuckerberg Amps Up the A.I. Race (NYTimes)
- Meta says it’s winning the talent war with OpenAI (The Verge)
- Apple announces sweeping App Store changes in the EU (9to5Mac)
- Google launches Doppl, a new app that lets you visualize how an outfit might look on you (TechCrunch)
- TikTok, Instagram Plot TV Apps Following YouTube’s Success (The Information)
- Windows is getting rid of the Blue Screen of Death after 40 years (The Verge)
Weekend Longreads Suggestions:
- My Couples Retreat With 3 AI Chatbots and the Humans Who Love Them (Wired)
- AI is ruining houseplant communities online (The Verge)
See Privacy Policy at https://art19.com/privacy and California Privacy Notice at https://art19.com/privacy#do-not-sell-my-info.
Doug, Dylan and Jon on Lip-Bu, Labubu, AI Salaries, and Bees
ChinaTalk •

Inside Cerebral Valley: Autonomous Vehicles & AI Investment
The Cerebral Valley Podcast •

Today on the pod, we're bringing you two of the liveliest panels from the 2025 Cerebral Valley AI Summit, held this week in London.
Both panels — “The Autonomous Vehicle Rollout” and “Investing in 2030” — explore one of the major themes from the event: where AI is poised to show up next in our everyday lives, beyond the chatbot. Think voice, devices, and even your car.
First up, we'll hear from Uber CEO, Dara Khosrowshahi, and Alex Kendall, Co-founder and CEO of Wayve, who are teaming up to bring self-driving cars to the UK.
Then we turn to the investor perspective, with top European VCs — Philippe Botteri of Accel, Tom Hulme of Google Ventures, and Jan Hammer of Index Ventures — on where they see the biggest AI opportunities for founders in the years ahead.
AI’s Unsung Hero: Data Labeling and Expert Evals
AI + a16z •

Labelbox CEO Manu Sharma joins a16z Infra partner Matt Bornstein to explore the evolution of data labeling and evaluation in AI — from early supervised learning to today’s sophisticated reinforcement learning loops.
Manu recounts Labelbox’s origins in computer vision, and then how the shift to foundation models and generative AI changed the game. The value moved from pre-training to post-training and, today, models are trained not just to answer questions, but to assess the quality of their own responses. Labelbox has responded by building a global network of “aligners” — top professionals from fields like coding, healthcare, and customer service, who label and evaluate data used to fine-tune AI systems.
The conversation also touches on Meta’s acquisition of Scale AI, underscoring how critical data and talent have become in the AGI race.
Here's a sample of Manu explaining how Labelbox was able to transition from one era of AI to another:
It took us some time to really understand like that the world is shifting from building AI models to renting AI intelligence. A vast number of enterprises around the world are no longer building their own models; they're actually renting base intelligence and adding on top of it to make that work for their company. And that was a very big shift.
But then the even bigger opportunity was the hyperscalers and the AI labs that are spending billions of dollars of capital developing these models and data sets. We really ought to go and figure out and innovate for them. For us, it was a big shift from the DNA perspective because Labelbox was built with a hardcore software-tools mindset. Our go-to market, engineering, and product and design teams operated like software companies.
But I think the hardest part for many of us, at that time, was to just make the decision that we're going just go try it and do it. And nothing is better than that: "Let's just go build an MVP and see what happens."
Follow everyone on X:
Check out everything a16z is doing with artificial intelligence here, including articles, projects, and more podcasts.
Legendary Consumer VC Predicts The Future Of AI Products
Y Combinator Startup Podcast •

Kirsten Green, founder of Forerunner Ventures, has backed some of the most iconic consumer brands of the past two decades — from Warby Parker to Chime to Dollar Shave Club.
In this conversation with Garry, she shares how great products (not marketing tricks) still win, why AI is unlocking a new kind of emotional relationship between consumers and technology, and what founders can learn from the messy creative stage we're in right now. She also breaks down how shifts in distribution, wellness, and digital behavior are reshaping what it means to build for real human needs.
Henrique Malvar - Episode 71
ACM ByteCast •
In this episode of ACM ByteCast, Rashmi Mohan hosts Henrique Malvar, a signal processing researcher at Microsoft Research (Emeritus). He spent more than 25 years at Microsoft as a distinguished engineer and chief scientist, leading the Redmond, Washington lab (managing more than 350 researchers). At Microsoft, he contributed to the development of audio coding and digital rights management for the Windows Media Audio, Windows Media Video, and to image compression technologies, such as HD Photo/JPEG XR formats and the RemoteFX bitmap compression, as well as to a variety of tools for signal analysis and synthesis. Henrique is also an Affiliate Professor at the Electrical and Computer Engineering Department at the University of Washington and a member of the National Academy of Engineers. He has published over 180 articles, has been issued over 120 patents, and has been the recipient for countless awards for his service. Henrique explains his early love of electrical engineering, building circuits from an early age growing up in Brazil, and later fulfilling his dream of researching digital signal processing at MIT. He describes his work as Vice President for Research and Advanced Technology at PictureTel, one of the first commercial videoconferencing product companies (later acquired by Polycom) and stresses the importance of working with customers to solve a variety of technical challenges. Henrique also shares his journey at Microsoft, including working on videoconferencing, accessibility, and machine learning products. He also offers advice to aspiring researchers and emphasizes the importance of diversity to research and product teams.
Episode 51: Why We Built an MCP Server and What Broke First
Vanishing Gradients •

How We Built Our AI Email Assistant: A Behind-the-Scenes Look at Cora
AI & I •

You don’t need to handle your inbox anymore. It’s Cora’s job now.
Cora is the AI chief of staff we built for your email at Every. It’s been in private beta for the last 6 months and currently manages email for 2,500 beta users—and today we’re making it available for anyone to use. Start your free 7-day trial by going to: https://cora.computer/
Cora is the $150K executive assistant that costs $15/month. Or $20/month if you want an Every subscription, too. This is what that actually means:
- Cora understands what’s important to you, screens your inbox, and only lets the most relevant emails through.
- The rest of your emails are summarized in a beautifully designed brief that’s sent to you twice a day.
- If it has enough context, Cora drafts replies for you in your voice.
- You can talk to Cora like you would your chief of staff—you can give it special instructions on how you want certain emails handled, ask it to summarize things, and even give you an opinion on complex decisions.
In this episode of AI & I, I sat down with the team behind Cora—Brandon Gell, head of the product studio; Kieran Klaassen, Cora’s general manager; and Nityesh Agarwal, engineer at Cora—for a closer look at how it all came together. We talk about:
- The story of the first time Brandon, Kieran, and I used Cora, while sipping wine at the Every retreat in Nice.
- The evolution of Cora’s categorization system, from a 4-hour vibe-coded prototype to a multi-faceted product with thousands of happy users.
- The features on Cora’s roadmap we’re most excited about: a unified brief across different email accounts, an iOS app, and an even more powerful assistant.
This is a must-watch if you’re curious about what it feels like to give Cora your inbox, and take back your life. Go to https://cora.computer/ to start your 7-day free trial now.
If you found this episode interesting, please like, subscribe, comment, and share!
Want even more?
Sign up for Every to unlock our ultimate guide to prompting ChatGPT here: https://every.ck.page/ultimate-guide-to-prompting-chatgpt. It’s usually only for paying subscribers, but you can get it here for free.
Sponsor: Experience high quality AI video generation with Google's most capable video model: Veo 3. Try it in the Gemini app at gemini.google with a Google AI Pro plan or get the highest access with the Ultra plan.
To hear more from Dan Shipper:
- Subscribe to Every: https://every.to/subscribe
- Follow him on X: https://twitter.com/danshipper
Timestamps:
- Introduction: 00:01:40
- Three ways Cora transforms your inbox (and your day): 00:04:21
- A live walkthrough of Cora’s features: 00:05:09
- The inside story of the first time Kieran, Brandon, and Dan used Cora: 00:12:13
- Train Cora like you would a trusted chief of staff: 00:16:30
- The AI tools that blew our minds while building Cora: 00:27:25
- How we build workflows that compound with AI at Every: 00:30:34
- The dream features that we’d like to put on Cora’s roadmap: 00:42:36
Links to resources mentioned in the episode:
- Try Cora now with a 7-day free trial: cora.computer
- The episode about how Kieran and Nityesh use Claude Code to build Cora: "How Two Engineers Ship Like a Team of 15 With AI Agents"
Claude Is Learning to Build Itself - Anthropic’s Michael Gerstenhaber on Agentic AI
Superhuman AI: Decoding the Future •

AI is evolving faster than anyone expected and we may already be seeing the early signs of superintelligence.
In this episode of the Superhuman AI Podcast, we sit down with Michael Gerstenhaber, Head of Product at Anthropic (makers of Claude AI), to explore:
- How AI models have transformed in just one year
- Why coding is the ultimate benchmark for AI progress
- How Claude is learning to code through agentic loops
- What "post-language model" intelligence might look like
- Whether superintelligence is already here — and we’ve just missed it
From autonomous coding to the rise of AI agents, this episode offers a glimpse into the next phase of artificial intelligence and how it could change everything.
Subscribe for deep conversations on AI, agents, and the future of intelligence.
Learn more about the Google for Startups Cloud Program here:
https://cloud.google.com/startup/apply?utm_source=cloud_sfdc&utm_medium=et&utm_campaign=FY21-Q1-global-demandgen-website-cs-startup_program_mc&utm_content=superhuman_dec&utm_term=-
Better Value Sooner Safer Happier • Simon Rohrer & Eduardo da Silva
GOTO - The Brightest Minds in Tech •

This interview was recorded for the GOTO Book Club.
http://gotopia.tech/bookclub
Read the full transcription of the interview here
Simon Rohrer - Co-Author of "Better Value Sooner Safer Happier" & Senior Director at Saxo Bank
Eduardo da Sliva - Independent Consultant on Organization, Architecture, and Leadership Modernization
RESOURCES
Simon
https://bsky.app/profile/simon.bvssh.com
https://mastodon.social/@simonr
https://x.com/sirohrer
https://www.linkedin.com/in/simonrohrer
https://github.com/sirohrer
https://www.soonersaferhappier.com
Eduardo
https://bsky.app/profile/esilva.net
https://mastodon.social/@eduardodasilva
https://x.com/emgsilva
https://www.linkedin.com/in/emgsilva
https://github.com/emgsilva
https://esilva.net
DESCRIPTION
Eduardo da Silva and Simon Rohrer discuss the core ideas of "Better Value Sooner Safer Happier" diving into the principles of organizational transformation.
Simon shares insights on the shift from output-driven to outcome-focused thinking, emphasizing value over productivity, and the need for continuous improvement in delivery speed, stakeholder satisfaction, and safety.
The conversation explores key concepts like technical excellence, integrating safety into development, and balancing incremental changes with occasional larger steps.
Simon Rohrer discusses organizational patterns and the importance of decentralizing decision-making, recommending a flexible, context-driven approach to transformation. The session concludes with practical advice on how to start implementing these ideas, using the book’s map to guide organizations toward the right transformation strategy based on their specific goals.
RECOMMENDED BOOKS
Jonathan Smart, Zsolt Berend, Myles Ogilvie & Simon Rohrer • Sooner Safer Happier
Stephen Fishman & Matt McLarty • Unbundling the Enterprise
Carliss Y. Baldwin • Design Rules, Vol. 2
Matthew Skelton & Manuel Pais • Team Topologies
Forsgren, Humble & Kim • Accelerate: The Science of Lean Software and DevOps
Kim, Humble, Debois, Willis & Forsgren • The DevOps Handbook
Bluesky
Twitter
Instagram
LinkedIn
Facebook
CHANNEL MEMBERSHIP BONUS
Join this channel to get early access to videos & other perks:
https://www.youtube.com/channel/UCs_tLP3AiwYKwdUHpltJPuA/join
Looking for a unique learning experience?
Attend the next GOTO conference near you! Get your ticket: gotopia.tech
SUBSCRIBE TO OUR YOUTUBE CHANNEL - new videos posted daily!
Highlights: #217 – Beth Barnes on the most important graph in AI right now — and the 7-month rule that governs its progress
80k After Hours •
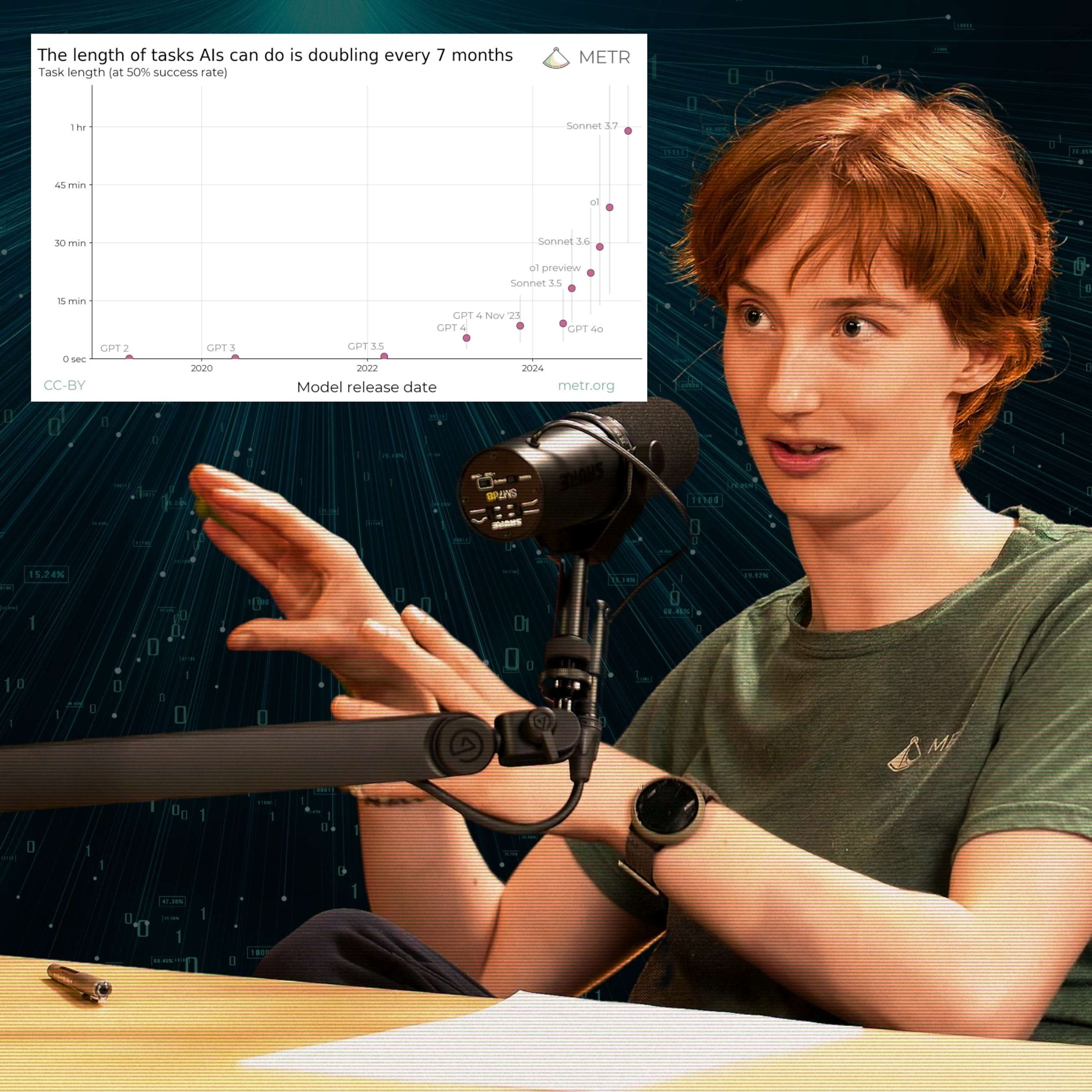
AI models today have a 50% chance of successfully completing a task that would take an expert human one hour. Seven months ago, that number was roughly 30 minutes — and seven months before that, 15 minutes.
These are substantial, multi-step tasks requiring sustained focus: building web applications, conducting machine learning research, or solving complex programming challenges.
Today’s guest, Beth Barnes, is CEO of METR (Model Evaluation & Threat Research) — the leading organisation measuring these capabilities.
These highlights are from episode #217 of The 80,000 Hours Podcast: Beth Barnes on the most important graph in AI right now — and the 7-month rule that governs its progress, and include:
- Can we see AI scheming in the chain of thought? (00:00:34)
- We have to test model honesty even before they're used inside AI companies (00:05:48)
- It's essential to thoroughly test relevant real-world tasks (00:10:13)
- Recursively self-improving AI might even be here in two years — which is alarming (00:16:09)
- Do we need external auditors doing AI safety tests, not just the companies themselves? (00:21:55)
- A case against safety-focused people working at frontier AI companies (00:29:30)
- Open-weighting models is often good, and Beth has changed her attitude about it (00:34:57)
These aren't necessarily the most important or even most entertaining parts of the interview — so if you enjoy this, we strongly recommend checking out the full episode!
And if you're finding these highlights episodes valuable, please let us know by emailing podcast@80000hours.org.
Highlights put together by Ben Cordell, Milo McGuire, and Dominic Armstrong
Humanizing Your AI Communications Strategy with Edelman Global Chair of AI Brian Buchwald
Shift AI Podcast •

In this episode of the Shift AI Podcast, Boaz Ashkenazy welcomes Brian Buchwald, who leads AI strategy and product development at Edelman, the world's largest communications firm. With his impressive background spanning investment banking, ad tech, digital media, and entrepreneurship, Buchwald offers a unique perspective on how AI is transforming both internal operations and client services at global scale.
Discover how Edelman is implementing AI across its 7,000-employee organization and for its prestigious client roster. Buchwald shares fascinating insights on the balance between automation and human expertise, the evolution of trust in the AI era, and how communications professionals are quantifying their impact. Whether you're interested in AI implementation at enterprise scale or the future of knowledge work, this episode reveals how "curated automation" is redefining an entire industry while keeping the human element at its core.
Chapters:
[00:00] Introduction to Brian Buchwald and Edelman
[03:09] Brian's Career Journey from Ad Tech to Communications
[05:35] Four Lenses of AI Implementation at Edelman
[06:59] Trust Quantification and Research Transformation
[10:17] Trust and AI: The Public Perception
[13:01] Three-Tiered Approach to Client Transformation
[17:55] Measuring Business Value in Communications
[21:48] The Human-Machine Partnership in Creative Work
[24:11] Mentors and Strategic Influences
[29:11] The Future of Work: Curated Automation
Connect with Brian Buchwald
LinkedIn: https://www.linkedin.com/in/brian-buchwald-0447591/
Email: brian.buchwald@edelman.com
Connect with Boaz Ashkenazy
LinkedIn: https://www.linkedin.com/in/boazashkenazy
Email: shift@augmentedailabs.com
The Shift AI Podcast is syndicated by GeekWire, and we are grateful to have the show sponsored by Augmented AI Labs. Our theme music was created by Dave Angel
Follow, Listen, and Subscribe
Spotify | Apple Podcast | Youtube
You’ve got 99 problems but data shouldn’t be one
The Stack Overflow Podcast •

Tobiko Data is creating a new standard in data transformation with their Cloud and SQL integrations. You can keep up with their work by joining their Slack community.
Connect with Toby on LinkedIn.
Connect with Iaroslav on LinkedIn.
Congrats to Stellar Answer badge winner Christian C. Salvadó, whose answer to What's a quick way to comment/uncomment lines in Vim? was saved by over 100 users.
Unlocking Enterprise Efficiency Through AI Orchestration - Kevin Kiley of Airia
The AI in Business Podcast •

Today’s guest is Kevin Kiley, President of Airia. With extensive experience helping large enterprises implement secure and scalable AI systems, Kevin joins Emerj Editorial Director Matthew DeMello to explore how agentic AI is reshaping enterprise workflows across industries like financial services. He explains how these systems differ from traditional AI by enabling autonomous action across connected environments—introducing both new efficiencies and new risks. Kevin breaks down a phased roadmap for adoption, from quick wins to broader orchestration, and shares key lessons from working with organizations navigating complex compliance, data governance, and access control challenges. He also highlights the growing importance of real-time safeguards and defensive security strategies as AI capabilities — and threats — continue to evolve. This episode is sponsored by Airia. Want to share your AI adoption story with executive peers? Click emerj.com/expert2 for more information and to be a potential future guest on the ‘AI in Business’ podcast!
Windows killed the Blue Screen of Death
TechCrunch Daily Crunch •

Bill Gates-backed AirLoom begins building its first power plant
TechCrunch Industry News •

Managing Deployments and DevOps at Scale with Tom Elliott
The Scaling Tech Podcast •

Thu. 06/26 – Conflicting AI Legal Rulings
Techmeme Ride Home •
The legal rulings on AI are finally coming in. The problem is, they’re contradictory, so we’re not getting any legal clarity yet. Creative Commons but for AI training data. Is DeepSeek’s R2 model being stymied by lack of access to Nvidia chips? And another deep look at the question of: is AI taking jobs at tech companies, right now?
Links:
- Microsoft sued by authors over use of books in AI training (Reuters)
- Trump Mobile reiterates claims that new phones are 'made in America' (USAToday)
- Creative Commons debuts CC signals, a framework for an open AI ecosystem (TechCrunch)
- OpenAI, Microsoft Rift Hinges on How Smart AI Can Get (WSJ)
- DeepSeek’s Progress Stalled by U.S. Export Controls (The Information)
- Salesforce CEO Says 30% of Internal Work Is Being Handled by AI (Bloomberg)
- AI Killed My Job: Tech workers (Blood In The Machine)
See Privacy Policy at https://art19.com/privacy and California Privacy Notice at https://art19.com/privacy#do-not-sell-my-info.
A Big Ruling on LLM Training and Midsummer Mail on NBA Salaries in Tech, Starting from Scratch in 2025, and More
Sharp Tech with Ben Thompson •

Optimizing Data Workflows with Emily Riederer | Season 6 Episode 8
Casual Inference •
- Emily: @emilyriederer.bsky.social
- Ellie: @epiellie.bsky.social
- Lucy: @lucystats.bsky.social
Bucky Moore: The Next Decade of AI Infrastructure
Generative Now | AI Builders on Creating the Future •

This week, Lightspeed Partner Mike Mignano sits down with his colleague Bucky Moore, a fellow partner at Lightspeed to explore the rapidly shifting landscape of AI and infrastructure. They unpack the evolution from hardware to cloud to AI-native architectures, the growing momentum behind open-source models, and the rise of AI agents and reinforcement learning environments. Bucky also shares how his early days at Cisco shaped his bottom-up view of enterprise software, and why embracing the new is the key to spotting trillion-dollar opportunities.
Episode Chapters:
(00:00) Introduction to the Conversation
(00:38) Bucky Moore's Background and Early Career
(01:39) Insights from Cisco: Old World Meets New World
(03:54) Transition to Venture Capital
(08:15) The Evolution of Infrastructure Investment
(15:50) Impact of AI on Infrastructure
(24:37) Training AI Agents: Challenges and Innovations
(25:07) The Future of Reinforcement Learning Environments
(25:51) Infrastructure for AI Agents
(26:49) Emerging Opportunities in AI Infrastructure
(28:58) The Impact of Salesforce's Data Policies
(33:00) The Evolution of AI Compute
(39:47) The Role of New AI Architectures
(42:47) The Future of Venture Capital in AI
(46:44) Predicting the Next Trillion-Dollar AI Companies
Stay in touch:
LinkedIn: https://www.linkedin.com/company/lightspeed-venture-partners/
Instagram: https://www.instagram.com/lightspeedventurepartners/
Subscribe on your favorite podcast app: generativenow.co
Email: generativenow@lsvp.com
The content here does not constitute tax, legal, business or investment advice or an offer to provide such advice, should not be construed as advocating the purchase or sale of any security or investment or a recommendation of any company, and is not an offer, or solicitation of an offer, for the purchase or sale of any security or investment product. For more details please see lsvp.com/legal.
The AI infrastructure stack with Jennifer Li, a16z
Complex Systems with Patrick McKenzie (patio11) •

In this episode, Patrick McKenzie (@patio11) is joined by Jennifer Li, a general partner at a16z investing in enterprise, infrastructure and AI. Jennifer breaks down how AI workloads are creating new demands on everything from inference pipelines to observability systems, explaining why we're seeing a bifurcation between language models and diffusion models at the infrastructure level. They explore emerging categories like reinforcement learning environments that help train agents, the evolution of web scraping for agentic workflows, and why Jennifer believes the API economy is about to experience another boom as agents become the primary consumers of software interfaces.
–
Full transcript:
www.complexsystemspodcast.com/the-ai-infrastructure-stack-with-jennifer-li-a16z/
–
Sponsor: Vanta
Vanta automates security compliance and builds trust, helping companies streamline ISO, SOC 2, and AI framework certifications. Learn more at https://vanta.com/complex
–
Links:
- Jennifer Li’s writing at a16z https://a16z.com/author/jennifer-li/
–
Timestamps:
(00:00) Intro
(00:55) The AI shift and infrastructure
(02:24) Diving into middleware and AI models
(04:23) Challenges in AI infrastructure
(07:07) Real-world applications and optimizations
(15:15) Sponsor: Vanta
(16:38) Real-world applications and optimizations (cont’d)
(19:05) Reinforcement learning and synthetic environments
(23:05) The future of SaaS and AI integration
(26:02) Observability and self-healing systems
(32:49) Web scraping and automation
(37:29) API economy and agent interactions
(44:47) Wrap
Satya Nadella: Microsoft’s AI Bets, Hyperscaling, Quantum Computing Breakthroughs
Y Combinator Startup Podcast •

A fireside with Satya Nadella on June 17, 2025 at AI Startup School in San Francisco.Satya Nadella started at Microsoft in 1992 as an engineer. Three decades later, he’s now Chairman & CEO, navigating the company through one of the most profound technological shifts yet: the rise of AI.In this conversation, he shares how Microsoft is thinking about this moment— from the infrastructure needed to train frontier models, to the social permission required to use that compute. He draws parallels to the early PC and internet eras, breaks down what makes a great team, and reflects on what he’d build if he were starting his career today.
#213 - Midjourney video, Gemini 2.5 Flash-Lite, LiveCodeBench Pro
Last Week in AI •
Our 213nd episode with a summary and discussion of last week's big AI news! Recorded on 06/21/2025
Hosted by Andrey Kurenkov and Jeremie Harris. Feel free to email us your questions and feedback at contact@lastweekinai.com and/or hello@gladstone.ai
Read out our text newsletter and comment on the podcast at https://lastweekin.ai/.
In this episode:
- Midjourney launches its first AI video generation model, moving from text-to-image to video with a subscription model offering up to 21-second clips, highlighting the affordability and growing capabilities in AI video generation.
- Google's Gemini AI family updates include high-efficiency models for cost-effective workloads, and new enhancements in Google's search function now allow for voice interactions.
- The introduction of two new benchmarks, Live Code Bench Pro and Abstention Bench, aiming to test and improve the problem-solving and abstention capabilities of reasoning models, revealing current limitations.
- OpenAI wins a $200 million US defense contract to support various aspects of the Department of Defense, reflecting growing collaborations between tech companies and government for AI applications.
Timestamps + Links:
- (00:00:10) Intro / Banter
- (00:01:32) News Preview
- Tools & Apps
- (00:02:12) Midjourney launches its first AI video generation model, V1
- (00:05:52) Google’s Gemini AI family updated with stable 2.5 Pro, super-efficient 2.5 Flash-Lite
- (00:07:59) Google’s AI Mode can now have back-and-forth voice conversations
- (00:10:13) YouTube to Add Google’s Veo 3 to Shorts in Move That Could Turbocharge AI on the Video Platform
- Applications & Business
- (00:11:10) The ‘OpenAI Files’ will help you understand how Sam Altman’s company works
- (00:12:29) OpenAI drops Scale AI as a data provider following Meta deal
- (00:13:28) Amazon’s Zoox opens its first major robotaxi production facility
- Projects & Open Source
- (00:15:20) LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
- (00:19:45) AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions
- (00:22:49) MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
- Research & Advancements
- Policy & Safety
See Why GenAI Workloads Are Breaking Observability with Wayne Segar
Screaming in the Cloud •

What happens when you try to monitor something fundamentally unpredictable? In this featured guest episode, Wayne Segar from Dynatrace joins Corey Quinn to tackle the messy reality of observing AI workloads in enterprise environments. They explore why traditional monitoring breaks down with non-deterministic AI systems, how AI Centers of Excellence are helping overcome compliance roadblocks, and why “human in the loop” beats full automation in most real-world scenarios.
From Cursor’s AI-driven customer service fail to why enterprises are consolidating from 15+ observability vendors, this conversation dives into the gap between AI hype and operational reality, and why the companies not shouting the loudest about AI might be the ones actually using it best.
Show Highlights
(00:00) - Cold Open
(00:48) – Introductions and what Dynatrace actually does
(03:28) – Who Dynatrace serves
(04:55) – Why AI isn't prominently featured on Dynatrace's homepage
(05:41) – How Dynatrace built AI into its platform 10 years ago
(07:32) – Observability for GenAI workloads and their complexity
(08:00) – Why AI workloads are "non-deterministic" and what that means for monitoring
(12:00) – When AI goes wrong
(13:35) – “Human in the loop”: Why the smartest companies keep people in control
(16:00) – How AI Centers of Excellence are solving the compliance bottleneck
(18:00) – Are enterprises too paranoid about their data?
(21:00) – Why startups can innovate faster than enterprises
(26:00) – The "multi-function printer problem" plaguing observability platforms
(29:00) – Why you rarely hear customers complain about Dynatrace
(31:28) – Free trials and playground environments
About Wayne Segar
Wayne Segar is Director of Global Field CTOs at Dynatrace and part of the Global Center of Excellence where he focuses on cutting-edge cloud technologies and enabling the adoption of Dynatrace at large enterprise customers. Prior to joining Dynatrace, Wayne was a Dynatrace customer where he was responsible for performance and customer experience at a large financial institution.
Links
Dynatrace website: https://dynatrace.com
Dynatrace free trial: https://dynatrace.com/trial
Dynatrace AI observability: https://dynatrace.com/platform/artificial-intelligence/
Wayne Segar on LinkedIn: https://www.linkedin.com/in/wayne-segar/
Sponsor
Dynatrace: http://www.dynatrace.com
Building Production-Grade RAG at Scale
The Data Exchange with Ben Lorica •

Douwe Kiela, Founder and CEO of Contextual AI, discusses why RAG isn’t obsolete despite massive context windows, explaining how RAG 2.0 represents a fundamental shift to treating retrieval-augmented generation as an end-to-end trainable system.
Subscribe to the Gradient Flow Newsletter 📩 https://gradientflow.substack.com/
Subscribe: Apple · Spotify · Overcast · Pocket Casts · AntennaPod · Podcast Addict · Amazon · RSS.
Detailed show notes - with links to many references - can be found on The Data Exchange web site.
Novoloop is making tons of upcycled plastic
TechCrunch Industry News •
Google unveils Gemini CLI
TechCrunch Daily Crunch •
Databricks, Perplexity co-founder pledges $100M on new fund for AI researchers
TechCrunch Startup News •

How a data processing problem at Lyft became the basis for Eventual
TechCrunch Industry News •
#511: From Notebooks to Production Data Science Systems
Talk Python To Me •

Episode sponsors
Agntcy
Sentry Error Monitoring, Code TALKPYTHON
Talk Python Courses
Links from the show
Catherine Nelson LinkedIn Profile: linkedin.com
Catherine Nelson Bluesky Profile: bsky.app
Enter to win the book: forms.google.com
Going From Notebooks to Scalable Systems - PyCon US 2025: us.pycon.org
Going From Notebooks to Scalable Systems - Catherine Nelson – YouTube: youtube.com
From Notebooks to Scalable Systems Code Repository: github.com
Building Machine Learning Pipelines Book: oreilly.com
Software Engineering for Data Scientists Book: oreilly.com
Jupytext - Jupyter Notebooks as Markdown Documents: github.com
Jupyter nbconvert - Notebook Conversion Tool: github.com
Awesome MLOps - Curated List: github.com
Watch this episode on YouTube: youtube.com
Episode #511 deep-dive: talkpython.fm/511
Episode transcripts: talkpython.fm
--- Stay in touch with us ---
Subscribe to Talk Python on YouTube: youtube.com
Talk Python on Bluesky: @talkpython.fm at bsky.app
Talk Python on Mastodon: talkpython
Michael on Bluesky: @mkennedy.codes at bsky.app
Michael on Mastodon: mkennedy
Episode 46: Software Composition Is the New Vibe Coding
Vanishing Gradients •
D2DO276: MCP: Capable, Insecure, and On Your Network Today
Day Two DevOps •
Wed. 06/25 – Never Wear A Suit In Tech
Techmeme Ride Home •
AI is transforming job search on both sides of the equation. A first court ruling on using copyrighted books to train AI. New AI releases from Google devs will want to know about. How your kids 3rd grade teacher is using AI. And why did Apple push an ad to everybody?
Sponsors:
Links:
- Employers Are Buried in A.I.-Generated Résumés (NYTimes)
- CareerBuilder + Monster to Sell Businesses in Bankruptcy (WSJ)
- Exclusive: Uber and Palantir alums raise $35M to disrupt corporate recruitment with AI (Fortune)
- Anthropic wins a major fair use victory for AI — but it’s still in trouble for stealing books (The Verge)
- Google unveils Gemini CLI, an open-source AI tool for terminals (TechCrunch)
- How ChatGPT and other AI tools are changing the teaching profession (AP)
- iPhone customers upset by Apple Wallet ad pushing ‘F1’ movie (TechCrunch)
See Privacy Policy at https://art19.com/privacy and California Privacy Notice at https://art19.com/privacy#do-not-sell-my-info.
859: BAML: The Programming Language for AI, with Vaibhav Gupta
Super Data Science: ML & AI Podcast with Jon Krohn •

RAG Benchmarks with Nandan Thakur - Weaviate Podcast #124!
Weaviate Podcast •

Nandan Thakur is a Ph.D. student at the University of Waterloo! Nandan has worked on many of the most impactful works in Retrieval-Augmented Generation (RAG) and Information Retrieval. His work ranges from benchmarks such as BEIR, MIRACLE, TREC, and FreshStack, to improving the training of embedding models and re-rankings, and more!
(Preview) The PRC and the Past Two Weeks in Iran; Ten Speeches in Taiwan; London Framework Faltering?; All Eyes on the EU
Sharp China with Bill Bishop •

Episode 42: Learning, Teaching, and Building in the Age of AI
Vanishing Gradients •
Chinar Movsisyan: How to Deliver End-to-End AI Solutions
ConTejas Code •

Links
- Codecrafters (sponsor): https://tej.as/codecrafters
- Feedback Intelligence: https://www.feedbackintelligence.ai/
- Chinar on X: https://x.com/movsisyanchinar
Summary
In this podcast episode, we talk to Chinar Movsisyan, the CEO and founder of Feedback Intelligence. They discuss Chinar's extensive background in AI, including her experience in machine learning and computer vision. We discuss the challenges faced in bridging the gap between technical and non-technical stakeholders, the practical applications of feedback intelligence in enhancing user experience, and the importance of identifying failure modes. The discussion also covers the role of LLMs in the architecture of Feedback Intelligence, the company's current stage, and how it aims to make feedback actionable for businesses.
Chapters
00:00 Chinar Movsisyan
02:08 Introduction to Feedback Intelligence
03:23 Chinar Movsisyan's Background and Expertise
06:33 Understanding AI Engineer vs. GenAI Engineer
09:08 The Lifecycle of Building an AI Application
13:27 Data Collection and Cleaning Challenges
16:20 Training the AI Model: Process and Techniques
24:48 Deploying and Monitoring AI Models in Production
27:55 The Birth of Feedback Intelligence
31:58 Understanding Feedback Intelligence
33:26 Practical Applications of Feedback Intelligence
42:13 Identifying Failure Modes
45:58 The Role of LLMs in Feedback Intelligence
51:25 Company Stage and Future Directions
57:24 Making Feedback Actionable
01:01:30 Streamlining Processes with Automation
01:03:18 The Journey of a First-Time Founder
01:05:48 Wearing Many Hats: The Founder Experience
01:08:22 Prioritizing Features in Early Startups
01:13:09 Learning from Customer Interactions
01:16:38 The Importance of Problem-Solving
01:21:51 Handling Rejection and Staying Motivated
01:27:43 Marketing Challenges for Founders
01:29:23 Future Plans and Scaling Strategies
Hosted on Acast. See acast.com/privacy for more information.
Codename Goose - Your Next Open Source AI Agent
The Square Developer Podcast •

Richard Moot: Hello and welcome to another episode of the Square Developer Podcast. I'm your host, Richard Moot, head of developer relations here at Square. And today I'm joined by my fellow developer relations engineer, Rizel, who's over working on Block Open Source. Hi Rizel, welcome to the podcast.
Rizel Scarlett: Hey, Richard. Thanks for having me. And I know it's so cool. We're like coworkers, but on different teams
Richard Moot: And you get to work on some of the, I'll admit I'm a little bit jealous. You get to work on some of the cool open source stuff, but I still get to poke around in there occasionally. But today we wanted to talk about one of our most recent releases is Goose, and I would like you to do the honors of, give us the quick pitch. What is Goose?
Rizel Scarlett: Goose is an on machine AI agent and it's open source. So when I say on machine, it's local. Unlike a lot of other AI tools that you use via the cloud, you have everything stored on your computer, private, you have control over the data, and you get to interact with different lms. You can choose whichever you want, whether it's GPT, sonnet, 3.5, whatever you prefer, you get to bring it.
Richard Moot: Awesome. And so I'm going to hopefully give a little bit more because I want to just kind of clarify for Square developers who might be coming in, they're like, they're just building other APIs, SDKs, trying to extend stuff for square sellers. So when we're talking about an agent, an agent, I always end up thinking the matrix, the agents and the matrix. And from what I understand, it's not too far off. You give it instructions and it will actually go and do things on your machine for you write two files, edit files, run commands. It's almost like doing things that a person could do on your computer for you.
Rizel Scarlett: Yes, exactly. That's a really good description. It doesn't just edit code for you. It can control your system. So I had it dimmed, the lights on my computer open different applications. You can really just automate anything even if you didn't know how to code.
Richard Moot: Yeah, I mean that's one of the things that I didn't even really think about when I first tried Goose. So one of the fun benefits of working here at Block is that I got to have fun with it before it actually went live. And one thing that I didn't really think about until I tried the desktop client and I forgot to allow the plug, there's two different ways you can interact with it. There's the CLI and the terminal, and then there's a desktop client, which I think right now works on Mac os.
Rizel Scarlett: Yes,
Richard Moot: I know there's big requests and to have it work in more than just Windows.
Rizel Scarlett: Yeah. Yeah. Right now, I mean we do have what I think is a working version of Windows, but the experience for the build time is not great. So we're still working through that.
Richard Moot: Yeah, well, having my own wrestling with working with the Windows sub Linux, I only really think of it as WSL. I've had so many headaches of trying to deal with networking and connecting and when do I need to switch to the power show versus a terminal, and it's all the reason I end up falling back to doing all of my development on my Mac.
Rizel Scarlett: Yeah. I haven't used the Windows computer since I was an IT support person. I don't even know what the new developments are now.
Richard Moot: Yeah, I mean I recently got burned by that where I didn't realize that in order to do certain virtualization stuff, you had to have a specific version of Windows, like some professional version, and then that enabled virtualization to run a VM of something interesting.
I think since then they've baked in the Windows sub Linux thing, which is basically just running Ubuntu in a virtualization for you. But that was an eyeopener, but thankfully Microsoft's working on fixing these things, but we digress. So coming back to Goose and what is it that most people have that you've sort of seen from the community as they've been starting to try it out and use Goose?
Rizel Scarlett: Yeah, I mean I just see people, well, a lot of it is mainly developers. That's the larger side of just using it to automate a lot of the tasks that they are doing. Maybe setting up, what am I trying to say, the boilerplate for their code or just sometimes other different things. I see people wanting to build local models and just in general or doing things with their kids, but I've also seen people doing silly experiments. This is where I find a lot of fun where people are having Goose talk to Goose or having a team of different, I guess geese, a team of agents and they're basically running a whole bunch of stuff. So they had one Goose be the PM and it was instructing all the engineer agents to perform different tasks. So it's a varied amount of things, but a lot of people are just trying to make their lives easier and have Goose do the mundane task in the background while they do the creative things. I've just been doing fun silly stuff. Like I had Goose play tic-tac-toe with me just for fun. I just wanted to see if it could do that and that was cool. Yeah.
Richard Moot: Have you beat it yet?
Rizel Scarlett: Every time I'm disappointed.
Richard Moot: You think it'd be way more advanced? I mean tech to can kind of, if I'm not mistaken, I think based on who goes first, it can be a determined game as long as you play with perfect strategy.
Rizel Scarlett: Yeah, I told it to play competitively. I'm still working on the perfect prompt. You always let me win Goose what's going on.
Richard Moot: Maybe that's part of the underlying LLMs is that they want to be helpful and so they think they're being helpful by letting you win, otherwise you wouldn't have fun.
Rizel Scarlett: That's true.
Richard Moot: Well, one of the things I was very fascinated by when first trying out the desktop client versus the CLI, because I habitually used the CLI version, but when I first opened up the desktop client, I had asked, what is it that you can do? And one of the things that it suggested that never even occurred to me was using Apple Scripts to run certain automations on your system. And I immediately just went, okay, can you organize my downloads folder and put everything? And it just immediately put everything in organized folders. And that's something I used to, I mean years ago, write my own quick little scripts to be like, oh, I need to move all these CSVs into someplace and PDFs. And it just immediately did it for me and it was just, that was amazing because now I can actually find where the certain things are.
Rizel Scarlett: That's so awesome. Yeah, I think you might've been using the computer controller extension, and that might be my favorite so far just because of, oh my gosh, it could actually, it's not just writing code for me. I'm like, okay, cool. There's other stuff that can do that Cursor does that as well, but it can tap into my computer system if I give it permission and move things around. I did a computer controller extension tutorial and I was just making it do silly stuff. Like I mentioned, it dimmed my computer screen. It opened up Safari and found classical music to play it, did some research on AI agents for me and put it in A CSV and then it turned back on the lights. It's so cool. I can just tell it, go do my own work for me and I'll it back.
Richard Moot: Yeah, that's great. And so you touched on something that I think is kind of an interesting part about it, and I feel like I want to come back to the part to really emphasize GOOSE is an open source project, and so it allows you to attach all of those various LLMs to sort of power the experience. But what you just touched on there is the extensions. So the way that it can do these things, could you tell us a little bit about what are extensions and how are they used by either Goose or the LLM? What is the relationship there?
Rizel Scarlett: Yeah, so extensions are basically, I guess you can think of it as extending it to different applications or different use cases. And we're doing that through a protocol called the Model Context Protocol, which Anthropic and us have been partnering on. And basically it allows any AI agent to kind of have access to different data. So for example, there's a Figma MCP or a model context protocol, and you can connect GOOSE to that MCP and tell it, Hey, here's some designs that I have, and Goose will be able to look at those and copy it rather than when you're maybe working with something like chat GBT, you have to go and give it context and be like, Hey, chat GBT, I'm working on this. Here's how this goes. And it takes up a lot of time. It'll just jump right in. And like you were saying, it's open source, so anybody can make MCP, you can connect it to any MCP out there that, I mean, some of them have to be honest, some CPS that are out there since it's open source, they don't all work, but the ones that do, you can connect it to Goose.
Richard Moot: Yeah. And so that's kind of like what you were originally talking about, the computer controller one.
Richard Moot: I'm going to hopefully describe this in a way that can make this visual for those that are listening in. But when you're using GOOSE in the terminal, when you first ever install it, it'll run you through a configuration of, Hey, it's basically setting up your profile and it says, which LLM do you want to connect to? And then you can kind of select from there and then it'll say, give me your credentials. And then after that you can get the option to, well actually maybe I'm jumping the gun here. I think it just gets you through storing that. And then you can have the option of once Goose is configured, you can toggle on certain extensions, extensions that are included, and then there's a process to actually go find these other ones that are published elsewhere and then add them in, right?
Rizel Scarlett: Yes, that's correct. We have your built-in extensions, like the developer extension, computer controller memory, and then you have the option to reach out to other extensions or even build your own custom extension and plug it in as well.
Richard Moot: Gotcha. And so the one I know that is the key one that's included with GOOSE is the developer extension. That's what does all the basic developer actions that you would think of, and then computer controller, that's kind of the one for doing more. Maybe tell me how is computer controller different than developer?
Rizel Scarlett: Yeah, so developer extension, it has the ability to run, shell command Shells scripts, so it'll go ahead and you say, create this file. It'll say touch create this file. It'll add the code for you in the places that it needs to. Whereas the computer controller, the intention of that is that it's supposed to be able to scrape the web, do different web interactions, be able to control your system, and then this is all automating things or even do automation scripts like you had mentioned before. These are all automating things for people who may not feel as comfortable coding, but they want to automate things within their system. That's the intention of the computer controller.
Richard Moot: Gotcha. And I'm curious, as this has been out there and having two different versions, I don't really want to say two different versions, two different ways of interacting with Goose with the desktop and the CLI, the desktop is really great for those that might not be more comfortable opening up a terminal. Have you seen folks coming in who are maybe less technical, who've been trying to actually use it through this way?
Richard Moot: Just curious all the various types of people that have been coming in and adopting or playing around with Goose.
Rizel Scarlett: Yeah. Well first side note, even though I'm comfortable with the terminal, I like using the desktop. I just think it looks more visually appealing for me. But I have seen people in Discord, I think there was a set of health professionals that they were part of a hackathon and they were using GOOSE to build whatever their submissions were. I don't know exactly what, but I thought that was interesting that they're going to build tools and submit to a hackathon even though they're not solely software engineers. So that's one example.
Richard Moot: Interesting. So it's been really interesting seeing all of the different ways that people have building on it. And I mean it's been pretty exciting seeing how people have really started to just start using it. One of the things I thought was interesting was it seemed like initially some people just didn't quite understand, and I'm sure there's just work to be done in general, not just for us, but for people trying to use agents that I think a lot of people have assumed initially like, oh, where's the LLM? Why is there no thing bundled with this? I feel like I can't do anything. And we're like, no, you have to connect it to something else. But the one that got me the most interested was trying to get it to talk to a local LLM. And so I've tinkered with this over the past couple of weekends of running a llama, getting a model running. But I will admit that I hit my own endpoint where I was like, okay, I have an LLM running, but it doesn't really work with the tool calling.
I think that's something maybe we talk a little bit, what is it tool calling is like that thing that how it uses the extensions. But maybe you can tell us a little bit about what is tool calling and why is it so important?
Rizel Scarlett: Yeah, I mean a lot of things you said that I want to touch on. First off agents, I think from not understanding how Goose will work, I think agents are still a fairly new concept and everybody is saying, oh, this is what an agent is, and they all have their different definitions. So when I first used Goose as well, I was a little bit confused. I was like, what is this supposed to do? I think similarly when Devin came out, people were like, this is not working how I thought it would. So that just happens. But yes, open source using Goose with an open source LLM is so powerful because Goose is an open source local AI agent, and then you have the local LLMs that you can leverage it with. So you can own your data and you don't even need internet to have the LLMs running.
Rizel Scarlett: But it is difficult. And like you said, tool calling. I am excited about this. I just came off of livestream with an engineer from alama. First off, the way he described tool calling was interesting. He said, it's not how I thought of it, but he was saying it's kind of how the LLM learns what it should or can do. So it's kind of like, oh, I have these set of tools here. Which one should I use for what I'm going to do? So let's say you told somebody I want to look up, or I want to go on a flight to, I don't know, Istanbul, I don't know why I picked that. What flights are available, how long will it take me? So then
Rizel Scarlett: An agent will be like, oh, tools do I have? And it might say, oh, I have a find flights tool and I have a MAP tool and I have this. So in order to find the flight, it might use that flights tool and in order to figure out the distance, it might use the MAPS tool or something like that. So that's kind of how it would work and it, I think it refines the results that it would have rather than looking at all these different things, it's like, okay, I'm going to use this particular tool and get this particular output. I learned a lot about open source models working with Goose or any agent, you have to, it's a lot of different prompting tips. First off, it's best probably to ask the open source LLM what access or what tools do I have access to? Because Open Source L LMS are much smaller, so they have a smaller context window and they're not able to interact with an agent like the cloud ones. They have so much more larger content with those, so they're able to take in more memory and stuff like that. So it's like I only have this amount, so let's get to what we need to do. Show me what tools are available. I'll grab that particular tool that's needed. And then another suggestion for when building an agent, and I think Goose will probably go in this direction to help improve the experience of working with open source. LLMs is having structured output. So the structured output would tell it kind of what it can and can't do and how the format of it would be printed out.
Richard Moot: Interesting.
Rizel Scarlett: I know I said a lot.
Richard Moot: No, no, no, that was great because it had me wondering with certain, when I started messing with one of the open source models and then I was trying to use it, I think the open source model I found was from somebody within Block who actually tried to fine tune a version of Deep Seek to be like, oh yeah, this one will work with tool calling. But then I think I was realizing I still needed probably an extension for it to actually make use of it because, and I think that's the part where maybe I misunderstood how these things work, but I'm sure that there's things that Goose does that it maybe tells the LLM almost pretext that is sent in the context. So before you even write your prompt, it has things that it will sort of give to be like, Hey, you have tools available to you or there's these tools. And so you might not see that in the terminal or in the desktop, but it's actually sort of adding these things at the beginning or maybe the end of the context to say, Hey, here's some tools available to you. Make sure that you use them. I'm oversimplifying, I'm sure, but that's kind of how I'm guessing that that might work.
Rizel Scarlett: That's how I seen it. So I looked at the logs because I wanted to really demo. I had no clue coming back from maternity leave that there was this little not necessarily working or trying to say obstacle, a little obstacle to work with open source LLMs and the agent. So I was like, oh, I'm ready to go. I'm going to go ahead and demo this live. And I realized, oh my gosh, it doesn't work perfectly. So I was looking at the logs and it does have a system prompt in the beginning where I didn't use deep seek like you did. I used Quinn 2.5 and it'll say in the beginning, you're a helpful assistant, you have access to computer controller and developer extension, and you can do this, this, and this. I think another limitation is our hardware as well. So even though it's on a local device, and I mean it's supposed to work on a local device, our local devices might not have enough RAM or memory. I have a 64 gigabyte, but the person that came on the live stream with me, he had 128, so that worked much better. So that might've been a limitation for you as well. And even though the system prompt already told it what extensions it would have, we both had a better result when we started off the conversation saying, Hey, what tools do you have access to? And it probably referred to the system prompt and then went ahead and printed it out to us.
Richard Moot: Yeah, yeah. And when I was tinkering with this, I actually was putting, I took an old gaming laptop basically set it up with, I converted it from Windows to Linux and it works reasonably well. It's still a little bit too slow for what I would actually want to be using it. So I have my regular gaming computer that I've actually, so when I want to mess with this, I actually just run a alarm on that when it's on, and then I use it as sort of a remote server and it's usable at that point. I think tokens don't fly through with the cloud LLMs. I mean it's still kind of slowish, but it's usable. And I think it's really fun to try out the local LLM stuff just, I mean as a developer, it gives me this mild peace of mind of my data's not going anywhere, so it feels safer somehow.
Rizel Scarlett: Yeah, you're such a tinkerer. I love that.
Richard Moot: Oh, I tinker with way too many things, network configurations, running clusters locally on my home lab, all stuff that I don't think I've ever used professionally, but I just love learning about this stuff.
Rizel Scarlett: I love that. I love that.
Richard Moot: So that kind of leads me one other thing that I'm interested in and I want to clarify. Not going to try to go into the realm of tips about using LLMs in augmenting our development workflows. And I think we're both in a similar camp of being in Devereux. It's really fun to just be like, I'm going to use this to start a new project or work in a language that I'm not usually familiar with and maybe see what I can build. I'm curious in terms of unprofessional tips, just things that you're sort of learning intuitively as you interact with it, how has it changed for you when you first started working with LLMs with doing software development to now? Have you ever noticed how you approach things a little bit differently?
Rizel Scarlett: That's a really good question. I haven't thought about it. I know when I, let me think because when I started using, my first experience with LLMs was like GitHub copilot and I made this whole playbook for people to use. I was like, make sure you have detailed examples and stuff like that, but how has it changed now?
Richard Moot: I'll give you an example. So to maybe help get your creative juices flowing on it. I know it's kind of coming out of left field, but when I first started using LLMs, I would just be like, Hey, can you build me this particular function? I think my first interaction was probably similar when I first used GitHub copilot and I was just doing tab completions and be like, I thought it was really cool that I could write a comment and describing the function that I want, and then I would start to write the function and then it would complete it out, and then I'd maybe have to edit a few things. And then once, I think it was when I first started using Goose is the first time I really tried one shotting things to be like build me an entire auth service for this app. And then I have now kind of swung back the other way a little bit where I tend to want to do a little bit more prompting when I want to do more of those one shots.
Rizel Scarlett: Interesting.
Richard Moot: But I've found that if I scaffold out half of it, maybe create the initial files and a single function or something and then it kind of fills in the rest, I have found it tends to work a little bit better. There's a few other tips that I can go into, but I don't know if that sort of helps. And that's how I've changed a little bit in how I've been using it because I've found that when you try doing the one shotting, it can just be too much that it's trying to do. And I feel like also it's too much context, especially I think one tip that I've heard continually with Goose and with others have a very clear what you considered a finished point and then move into a new context. Otherwise you can kind of go off the rails pretty fast.
Rizel Scarlett: Yeah, okay. I'll say this. I think my experience might be a little bit different just because when copilot came out, I had to demo GitHub copilot. So I was already thinking of, okay, how do I do this one-shot prompt that'll build out this whole thing so that people can be super impressed with me? So I think I was doing a lot of one-shot prompts and I probably brought over some of that learning from there. But
Rizel Scarlett: I think one thing I've been learning with building out the tutorials for Goose is kind of like what you're saying, how do I not let it get the context mixed up but still do a one-shot prompt? Because a lot of our tutorials, it's like we want to keep them short and sweet, so how do I make it do multiple things without overwhelming it or making it just fail? Sometimes it's like, I don't know what you want me to do, or it goes over the context limit. I leverage Goose hints a lot. So a lot of those different, most AI agents and AI tools have goose hints, cursor rules. I think Klein has its own thing as well. I dunno if you say Klein or Clean or whatever, but I dunno.
Richard Moot: I don't know what it is either.
Rizel Scarlett: Oh, okay. But they all have their own little, here's context for longer repeatable prompts. That way I use up less of the context window and I don't have to keep repeating myself like, Hey, make sure you set up this next JS thing. I'm already writing. We're going to use next JS and types script. We're going to use Tailwind or whatever it is, and then I can jump directly into the prompt that I want to do. And another thing I do, I don't know if this is weird, sometimes I ask Goose, how would you improve this prompt? I'll be like, I wrote this prompt and it failed. I'll open a new session. I'm like, how would you have improved this prompt? And it might give me a shorter one. So I don't know if I have these rules in my head, but I kind of just been really, really more experimental than I was in the past, I guess.
Richard Moot: Yeah, I think that's a really good thing to call out. I think that that's something that I had learned over time where even though I try to figure out a way to codify an approach, but I end up realizing these are just, I mean, it's weird. I feel like I'm going to describe this, I am the LLM, but they're tools and then you figure out, yeah, I try this one and it's not quite doing what I want, so I'm going to go try something else. And then I think what you said there was one that I've even tried and I didn't really even think about is so go, sometimes I'll switch LLM providers and I'd be like,I'm trying to do this over here and it's not working, and I give it, it gives me something else as a different context. I'm like, well, let's try and see if I feed that back over here, if that gets me the result I'm wanting. And so yeah, I think that's the biggest importance right now is to just be continually experimenting with it because I think as time goes on, we're going to end up learning different, I don't know, heuristics of shortcuts of trying to get what we want done. Sometimes I really like doing the one shots and then other times I'm like, I maybe scaffold something out and then I'm like, I'm just going to progressively iteratively work through this because I don't want it to. I think when I was trying to have it build an off service for an app, I was just too worried about it in one shoting it that I'd have one or two tiny bugs that are hard to catch somewhere.
Rizel Scarlett: That's true.
Richard Moot: And then I was just like, I really don't want to have to be going back through all these different methods and figure out like, oh yeah, I'm actually handling the Jot token incorrectly here. I'd rather just sort of progressively work through and feel confident in it and then be like, okay, I'll give a concrete example of one where I was using this library, I think it was called, it's a one-time password library for node js. I didn't realize that it was kind of really outdated and not maintained, and I implemented it in this app that I was working on, and I realized it wasn't working in the way that I anticipated, and then I was like, oh, there's an updated version of this library somewhere else that's more well adopted and being maintained. And so I was writing out the conversion, but I only converted say one of the sign-in function, and then once I had that one converted, I basically told my LLM, Hey, I'm switching from this library to this library and I've already done this particular function. Can you go through and update all of the other ones to use this new library?
Richard Moot: It did it, I would say nearly perfectly, which is pretty amazing. So I always find there's these little ways that you can be like, yeah, I'm going to do some of the manual work because it'll give me that confidence, but then lean on the LLM when I'm like, okay, I feel like I've done enough that it can finish it for me.
Rizel Scarlett: You know what? Now that you say more, it does make me think, I think I use a different workflow if I'm building versus I am doing developer advocacy work for it demoing or doing a tutorial. So if I am building, you're right, I probably first ask it what is its plan? And I do go more iteratively and I do try to do more of it and then let Goose jump in at certain areas. But if I'm doing a demonstration, I want it to be I do a one shot, which is an art in itself for it to be one shot and for it to be repeatable because AI is non-deterministic. So it could have worked with me once and I tried to demo it and then it never works again, and people were like, this didn't work. But yeah, I think that iterative process is really helpful for me when I say like, Hey, how are you going to go about this? And Okay, I'm going to do this part. You do this. And I always open up a new session when I feel like the conversation's been going long because I think, well, I know it loses context as it gets too big.
Richard Moot: Yeah, totally. I couldn't agree more on that part, and in fact, I've talked with some coworkers who've had mixed experiences with trying to use LLMs in their development work, but I think the thing that we just touched on there is that you have to just be dynamic in how you would use it and understand that you might not use it the same way in every context. And that's definitely what I've also learned when I've built out a fun example app for developer advocacy, just to build a proof of concept for the rest of my team to understand, hey, we can build an example and say next JS or Nest js or view or something, and I'm just using it to be like, Hey, I want you to one shot this out to basically get this mostly working to share something, but that's not how I build it When I'm like, Hey, I want to make this published and official for people to consume to say this is the way that you adopt Square. I would approach that very differently when using the LLM because I'd probably be curating my function signatures a little bit better and like, oh, this looks really good and understandable, and then have it fill out the rest
Richard Moot: Versus just one shotting things. If I was just going to have a one shot things, I would just probably tell people coming to our platform, so here's Goose, here's your LLM, go ahead and one shot your app.
Rizel Scarlett: That's all you need, just Goose. There you go. And I think you had mentioned a little earlier that different, sometimes you'll switch to a different LLM in addition to experimenting with those prompts. Different LLMs have different outputs, and I know on the roadmap we're planning to come out with, I guess different products come out with benches of here's how well this LLM works with our tool, so we're coming out with Goose Bench to say, okay, maybe if you want to do this type of process or build this type of app, then maybe Anthropics models might be best or maybe opening eyes or whatever.
Richard Moot: That would be really helpful because one other thing that I've been tinkering with when I try using an LLM for doing any kind of development work is I've actually, I think there's certain tools, I think one called Cursor New, but it basically just runs you through a series of give the project name a description, what libraries are using, and then it basically gives you prompts to feed in to create certain documents. But what I found interesting was the first one we'll do is say it'll help create a product requirements document, which I think we all call PRDs, but I'm just want to be super clear for people who might not know the lingo. And so I usually have it start out with creating the PRD, and then from there it'll create the code style guide and then it'll create your goose hints or cursor rules, and then I think finally it'll kind of create, I don't know how useful this one is, but it'll create a Read me of a progress tracker.
Richard Moot: That one I've found it's cool, but I've not found it to be totally useful because usually the only time it is useful is when I finally get to say the end of a task where I'm like, Hey, build out, scaffold out the project, and then at the end of it I say, go ahead and go update the progress file to clarify what has been built, what should be built next, and where are we at. Then I use that as the start of the next session of, Hey, check the progress thing to see where we are and what we need to build next, and then work from there. That's so smart. I like that it's really been useful for me, but at the same time, I would say by this fourth or fifth session, I don't know why it starts getting a little, I run into too many errors and I don't know if it's actually specific to the number of sessions or the particular feature that I'm building is maybe too complex and I need to spend more time breaking it into smaller pieces.
Rizel Scarlett: Interesting. I definitely, I want to try that on my own. I didn't think about saving it. I think the memory extension would do that as well for you maybe.
Richard Moot: Yeah, to be clear, I think in this instance I was using something like Cursor.
Rizel Scarlett: Okay.
Richard Moot: But I think I was wanting to try this with Goose. I do have the memory extension enabled, but I just haven't actually gotten to this is sort of what I've been doing on my own at home, but I definitely want to try this more with Goose, especially because Goose has goose hints and I can very easily convert my other rules to work for Goose. But yeah, it's been very useful for larger, more complex things that I've been building, but I still feel like it has its limitations.
Rizel Scarlett: Yeah, I like the challenge of figuring out what's stopping you and how do I get around this? And you're right, you did say you were using Cursor or some type of tool and I heard Goose in my head,
Richard Moot: But yeah, I found it really helpful just trying to just experiment with all the various different tools. There's a lot that I think all of us don't know. There's a lot of stuff to just keep figuring out. I just think that it's weird to say to someone like, Hey, I could tell you the different ways that you could use this, but I think right now most people should actually just figure out how it can work for them because I think if you go online, you can find people on all ends of the spectrum. There's some people they work on stuff that's so bespoke complex that they go, oh, LMS are just not useful for me. They're too bug ridden or the performance of the functions it creates isn't useful. I think those people are one end of the spectrum versus other of us who are like, oh my gosh, I spend most of my day doing architecture stuff like API architecture stuff, and so having an LLM to do the actual implementation of a design is huge unlock because I might come up with a great API design, but then I'm like, this is going to take me so long to code up and an LLM feels like a huge unlock,
Rizel Scarlett: And I really resonate with your point of figure out what works for you. You really just got to tinker with it and be like, I want to get this done and figure out how it'll apply to you because like you said, I could tell people one way, but I might not work in the same way as they do or I'm not working as complex stuff as them. Yeah,
Richard Moot: And not to anthropomorphize it too much, but I feel like it's probably not too dissimilar if somebody just said, Hey, out of nowhere they said, Hey, we gave you an assistant. You'd be like, I don't even know what I'm, you'd at first be like, what do I use the assistant for? Can you organize my files? It takes you a while to even figure out, okay, what can you do? What are you good at? You don't know until you actually have that, and so I think we all have to just start interacting with it and then we'll figure out where we actually want help. You might find out there's certain areas where we don't want it to help us in these things, but we do want it to help us in those other things.
Rizel Scarlett: Get to know the lm.
Richard Moot: Exactly. Yeah. Even the people who think, oh, I don't really like it for coding. You're like, yeah, but you might find out you hate writing super long complicated emails or reading super long, complicated emails. You'd be like, Hey, can you go ahead and give me the TLDR of this or write an email form? It can be that simple.
Rizel Scarlett
Sometimes I use LLMs to make sure my emails sound polite. Sometimes my emails don't come out polite, even though I'm not even throwing any shade, so if it sounds like I'm throwing shade, take it out.
Richard Moot: That's great. I think more people should be using that. Maybe I'm biased because being in the Devereux space, you get to interact with all kinds of folks.
Rizel Scarlett: Yes, that's true.
Richard Moot: And they all have very different communication styles, not to name names. We did have one person who in this square community who I actually was very thankful for them, but they spent so much time just finding every single bug in our APIs, and it drove some people a little bit crazy like, oh my gosh, he found another one, but then I'm just sitting here just like, yeah, thank you. This is free qa. This is amazing. I'm going to keep encouraging this person to keep saying this stuff. I don't find it annoying in the least
Rizel Scarlett: I could get it. I could understand it on both sides. As an engineer, you're like, no more work, but as a developer advocate, you're like, yay, my product's getting improved,
Richard Moot: And it's validating. They love the product so much, they want it to be better, so of course, let's go do that.
Rizel Scarlett: It's true. I love that.
Richard Moot: Yeah. Well, I think we're coming up on our time here. Thank you so much for coming here and telling us a little bit about Goose. I think here's probably a good point for us to sort of plug where can people go to learn more about Goose Blocks Open source or if they want to just sort of follow you to learn more about any of this stuff.
Rizel Scarlett: Yeah, I would, if I were an engineer or somebody interested in open source itself, I would go to github.com/block/goose, and if you wanted to go on the website or install it, I would go to block.github.io/goose and to find me on the internet, on any social media platform and Black gobys.
Richard Moot: Perfect, and I will also just do the extra plug of check out the Block, open Source YouTube, and if you want, you can also check out the Square Developer YouTube if you're interested in things on Square Developer, and if you are working on a project or you want to learn more about what you can build or what is available on Square, go to developer dot square up.com or you can follow us at Square Dev on X. Thank you so much for being here, and we'll see you next time.
Episode 48: HOW TO BENCHMARK AGI WITH GREG KAMRADT
Vanishing Gradients •
Austan Goolsbee on Central Banking as a Data Dog
Conversations with Tyler •

Austan Goolsbee is one of Tyler Cowen’s favorite economists—not because they always agree, but because Goolsbee embodies what it means to think like an economist. Whether he’s analyzing productivity slowdowns in the construction sector, exploring the impact of taxes on digital commerce, or poking holes in overconfident macro narratives, Goolsbee is consistently sharp, skeptical, and curious. A longtime professor at the University of Chicago’s Booth School and former chair of the Council of Economic Advisers under President Obama, Goolsbee now brings that intellectual discipline—and a healthy dose of humor—to his role as president of the Federal Reserve Bank of Chicago.
Tyler and Austan explore what theoretical frameworks Goolsbee uses for understanding inflation, why he’s skeptical of monetary policy rules, whether post-pandemic inflation was mostly from the demand or supply side, the proliferation of stablecoins and shadow banking, housing prices and construction productivity, how microeconomic principles apply to managing a regional Fed bank, whether the structure of the Federal Reserve system should change, AI's role in banking supervision and economic forecasting, stablecoins and CBDCs, AI's productivity potential over the coming decades, his secret to beating Ted Cruz in college debates, and more.
Read a full transcript enhanced with helpful links, or watch the full video on the new dedicated Conversations with Tyler channel.
Recorded March 3rd, 2025.
Help keep the show ad free by donating today!
Other ways to connect
- Follow us on X and Instagram
- Follow Tyler on X
- Follow Austan on X
- Sign up for our newsletter
- Join our Discord
- Email us: cowenconvos@mercatus.gmu.edu
- Learn more about Conversations with Tyler and other Mercatus Center podcasts here.
SE Radio 674: Vilhelm von Ehrenheim on Autonomous Testing
Software Engineering Radio - the podcast for professional software developers •

Vilhelm von Ehrenheim, co-founder and chief AI officer of QA.tech, speaks with SE Radio's Brijesh Ammanath about autonomous testing.
The discussion starts by covering the fundamentals, and how testing has evolved from manual to automated to now autonomous. Vilhelm then deep dives into the details of autonomous testing and the role of agents in autonomous testing.
They consider the challenges in adopting autonomous testing, and Wilhelm describes the experiences of some clients who have made the transition. Toward the end of the show, Vilhelm describes the impact of autonomous testing on the traditional QA career and what test professionals can do to upskill.
This episode is sponsored by Fly.io.
![]()
Jack Herrington: Model Context Protocol (MCP), Growing a YouTube Audience, Getting into Open Source
ConTejas Code •

Links
- Codecrafters (sponsor): https://tej.as/codecrafters
- Jack on YouTube: https://www.youtube.com/@jherr
- Jack on X: https://x.com/jherr
- Jack on Bluesky: https://bsky.app/profile/jherr.dev
- Tejas on X: https://x.com/tejaskumar_
- create-tsrouter-app: https://github.com/TanStack/create-tsrouter-app
Summary
In this discussion, Jack Harrington and I explore the transition from being a content creator to an open source contributor, discussing the challenges and rewards of both paths. Jack shares his journey from being a principal engineer to a YouTuber, and now to a key player in the open source community with TanStack. We explore the intricacies of YouTube's algorithm, the importance of marketing oneself, and the unique features of Tanstack that allow for a progressive development experience. We also touch on the future of Tanstack, its cross-platform capabilities, and the potential integration with React Native.
We also discuss AI! Specifically, we discuss the Model Context Protocol (MCP) and how it provides tools and resources to AI, enabling seamless integration with applications. We explore the potential of local development with MCP, emphasizing its advantages over traditional cloud-based solutions.
Chapters
00:00 Jack Herrington
06:11 Transitioning from Influencer to Open Source Contributor
09:10 The YouTube Journey: Challenges and Growth
12:13 Navigating the YouTube Algorithm and Marketing Yourself
15:09 The Shift to Open Source and Community Engagement
18:18 Creating Tanstack: A New Era in Development
20:55 The Unique Features of Tanstack and Its Ecosystem
24:09 Progressive Disclosure in Frameworks
26:54 Cross-Platform Capabilities of Tanstack
30:16 The Future of Tanstack and React Native Integration
40:05 Navigating the Tanstack Ecosystem
42:21 Understanding Model Context Protocol (MCP)
54:04 Integrating MCP with AI Applications
01:05:09 The Future of Local Development with MCP
01:11:03 Creating a Winamp Clone with AI
01:17:07 The Future of Front-End Development and AI
01:24:49 Connecting Dots: The Power of MCP and AI Tools
01:33:27 The Entrepreneurial Spirit: Beyond Money
01:39:27 Closing Thoughts and Future Collaborations
Hosted on Acast. See acast.com/privacy for more information.
Prompts as Functions: The BAML Revolution in AI Engineering
The Data Exchange with Ben Lorica •
David Hughes, Principal Data & AI Solution Architect at Enterprise Knowledge. Our discussion centers on BAML, a domain-specific language that transforms prompts into structured functions with defined inputs and outputs, enabling developers to create more deterministic and maintainable AI applications.
Subscribe to the Gradient Flow Newsletter 📩 https://gradientflow.substack.com/
Support our work by leaving a small tip 💰 https://buymeacoffee.com/gradientflow
Subscribe: Apple · Spotify · Overcast · Pocket Casts · AntennaPod · Podcast Addict · Amazon · RSS.
Detailed show notes - with links to many references - can be found on The Data Exchange web site.
Mark Chen: On AI’s New Frontiers
Tech Unheard •

Before leading research at OpenAI, Mark Chen was a self-proclaimed “late-bloomer” to computer science. He pivoted from an initial career in finance to heading up OpenAI’s frontiers research, where he led the teams that created DALL-E, developed Codex, and incorporated visual perception into GPT-4.
Mark tells Rene about his roundabout path to AI research and about how he integrates research and product development to drive scientific progress at OpenAI.
Tech Unheard is a podcast from Arm. Find each episode in your podcast feed monthly.
The Future of AI is built on Arm.
Tech Unheard is a custom podcast series from Arm and National Public Media. Executive Producers Erica Osher and Shannon Boerner. Project Manager Colin Harden. Creative Lead Producer Isabel Robertson. Editors Andrew Meriwether and Kelly Drake. Composer Aaron Levison. Arm production contributors include: Ami Badani (CMO), Claudia Brandon, Simon Jared (media), Jonathan Armstrong, Ben Webdell (creative), Sofia McKenzie (social), Kristen Ray (PR), and Saumil Shah (Chief of Staff to the CEO).
250: The Chat Interface Debate: Is Text Really the Future?
The Data Stack Show •

Highlights from this week’s conversation include:
- Dashboard vs. Chatbot Discussion (1:40)
- The Future of Chat Interfaces (3:03)
- Vibe Revenue Concept (6:36)
- AI's Early Days Compared to the Internet (10:14)
- OpenAI and Hardware Collaboration (13:09)
- Challenges of Hardware Development (16:20)
- Productivity in Programming Languages (18:18)
- Critique of 'Language is Dead' Posts (21:34)
- Legacy Systems in Use (22:34)
- Deterministic vs. Non-Deterministic Workflows (23:37)
- Final Thoughts and Takeaways (23:45)
The Data Stack Show is a weekly podcast powered by RudderStack, customer data infrastructure that enables you to deliver real-time customer event data everywhere it’s needed to power smarter decisions and better customer experiences. Each week, we’ll talk to data engineers, analysts, and data scientists about their experience around building and maintaining data infrastructure, delivering data and data products, and driving better outcomes across their businesses with data.
RudderStack helps businesses make the most out of their customer data while ensuring data privacy and security. To learn more about RudderStack visit rudderstack.com.
How did China come to dominate the world of electric cars?
MIT Technology Review Narrated •

Why Danny Boyle shot ‘28 Years Later’ on iPhones … and more tech news
TechCrunch Industry News •
AllSpice’s platform is the GitHub for electrical engineering teams
TechCrunch Startup News •
Amazon to spend over $4B to expand Prime delivery to rural communities
TechCrunch Daily Crunch •
Episode 43: Tales from 400+ LLM Deployments: Building Reliable AI Agents in Production
Vanishing Gradients •
Rebuilding from Inside: How John Waldmann Led an AI Shift Without Breaking His Team
Beyond The Prompt - How to use AI in your company •

In this episode, John Waldmann, CEO of Homebase, shares how the 10-year-old SaaS company blew up its roadmap and rebuilt around AI—from culture to code. He walks us through the shift from 20-page PRDs to lightning-fast demos, reclaiming product leadership, and pushing teams into their “oh shit” moment with AI.
We explore the leadership reckoning, cultural resistance, and practical playbook behind the transformation—and what it means for the future of SaaS, small businesses, and human-centered AI. If you're leading (or bracing for) an AI shift, this one’s packed with hard-earned lessons and honest insight.
Key Takeaways:
- You Can’t Wait for Buy-In—Leadership Means Pushing the Shift — John didn’t wait for excitement or alignment—he took back product leadership and forced the move toward AI. It wasn’t about consensus, it was about momentum. If you’re leading a team through this kind of shift, your job isn’t to ask for permission—it’s to create urgency before it's obvious.
- Speed Over Specs — Prototypes Are the New Strategy — Homebase moved from 20-page PRDs to live demos built in hours. That switch didn’t just make shipping faster—it changed the way teams learn, think, and listen to customers. The takeaway? Stop planning in the abstract. Ship something real, now.
- Culture Is the Real AI Roadblock — The hardest part of going AI-first isn’t tech—it’s trust, fear, and inertia. From engineers to support teams, John had to help people reach their “oh shit” moment with AI. That’s when change sticks. Until then, it’s just optional homework. Leaders need to make adoption inevitable.
- AI Should Bring You Closer to Your Customers, Not Farther — This episode isn’t about chasing shiny tools. It’s about using AI to reduce the noise—so your team can focus more on humans, not less. For John, pragmatic AI is about freeing up time, getting closer to customer problems, and making the org feel smaller, not colder.
LinkedIn: John Waldmann | LinkedIn
Homebase: All-in-one Employee Scheduling, Time Clocks, Payroll, & More | Homebase
00:00 Introduction and Initial Reactions to AI
00:31 Meet John Waldmann and the Story of Homebase
00:53 Reinventing Homebase as an AI-First Company
01:46 From PRDs to Prototypes: Building Faster, Learning Smarter
05:02 How AI Is Reshaping the Customer Experience
09:19 Culture Shock: Resistance, Skepticism, and AI Adoption
14:03 The End of SaaS as We Know It?
19:34 Leading Through Disruption: Ownership, Urgency, and Org Design
25:12 Forcing the Shift: Getting Teams to Embrace AI
27:50 Hiring the Unemployed—and Other Nontraditional Talent Bets
28:56 Curiosity > Credentials: What to Look for in AI-Ready Teams
31:57 New Expectations, OKRs, and Holding Teams Accountable
37:10 Serving Small Businesses Better with AI
44:52 Final Thoughts: Team Dynamics, Founder Risk, and What’s Next
📜 Read the transcript for this episode: Transcript of Rebuilding from Inside: How John Waldmann Led an AI Shift Without Breaking His Team |
For more prompts, tips, and AI tools. Check out our website: https://www.beyondtheprompt.ai/ or follow Jeremy or Henrik on Linkedin:
Henrik: https://www.linkedin.com/in/werdelin
Jeremy: https://www.linkedin.com/in/jeremyutley
Show edited by Emma Cecilie Jensen.
Agent Engineering with Pydantic + Graphs — with Samuel Colvin
Latent Space: The AI Engineer Podcast •

Did you know that adding a simple Code Interpreter took o3 from 9.2% to 32% on FrontierMath? The Latent Space crew is hosting a hack night Feb 11th in San Francisco focused on CodeGen use cases, co-hosted with E2B and Edge AGI; watch E2B’s new workshop and RSVP here!
We’re happy to announce that today’s guest Samuel Colvin will be teaching his very first Pydantic AI workshop at the newly announced AI Engineer NYC Workshops day on Feb 22! 25 tickets left.
If you’re a Python developer, it’s very likely that you’ve heard of Pydantic. Every month, it’s downloaded >300,000,000 times, making it one of the top 25 PyPi packages. OpenAI uses it in its SDK for structured outputs, it’s at the core of FastAPI, and if you’ve followed our AI Engineer Summit conference, Jason Liu of Instructor has given two great talks about it: “Pydantic is all you need” and “Pydantic is STILL all you need”.
Now, Samuel Colvin has raised $17M from Sequoia to turn Pydantic from an open source project to a full stack AI engineer platform with Logfire, their observability platform, and PydanticAI, their new agent framework.
Logfire: bringing OTEL to AI
OpenTelemetry recently merged Semantic Conventions for LLM workloads which provides standard definitions to track performance like gen_ai.server.time_per_output_token. In Sam’s view at least 80% of new apps being built today have some sort of LLM usage in them, and just like web observability platform got replaced by cloud-first ones in the 2010s, Logfire wants to do the same for AI-first apps.
If you’re interested in the technical details, Logfire migrated away from Clickhouse to Datafusion for their backend. We spent some time on the importance of picking open source tools you understand and that you can actually contribute to upstream, rather than the more popular ones; listen in ~43:19 for that part.
Agents are the killer app for graphs
Pydantic AI is their attempt at taking a lot of the learnings that LangChain and the other early LLM frameworks had, and putting Python best practices into it. At an API level, it’s very similar to the other libraries: you can call LLMs, create agents, do function calling, do evals, etc.
They define an “Agent” as a container with a system prompt, tools, structured result, and an LLM. Under the hood, each Agent is now a graph of function calls that can orchestrate multi-step LLM interactions. You can start simple, then move toward fully dynamic graph-based control flow if needed.
“We were compelled enough by graphs once we got them right that our agent implementation [...] is now actually a graph under the hood.”
Why Graphs?
* More natural for complex or multi-step AI workflows.
* Easy to visualize and debug with mermaid diagrams.
* Potential for distributed runs, or “waiting days” between steps in certain flows.
In parallel, you see folks like Emil Eifrem of Neo4j talk about GraphRAG as another place where graphs fit really well in the AI stack, so it might be time for more people to take them seriously.
Full Video Episode
Chapters
* 00:00:00 Introductions
* 00:00:24 Origins of Pydantic
* 00:05:28 Pydantic's AI moment
* 00:08:05 Why build a new agents framework?
* 00:10:17 Overview of Pydantic AI
* 00:12:33 Becoming a believer in graphs
* 00:24:02 God Model vs Compound AI Systems
* 00:28:13 Why not build an LLM gateway?
* 00:31:39 Programmatic testing vs live evals
* 00:35:51 Using OpenTelemetry for AI traces
* 00:43:19 Why they don't use Clickhouse
* 00:48:34 Competing in the observability space
* 00:50:41 Licensing decisions for Pydantic and LogFire
* 00:51:48 Building Pydantic.run
* 00:55:24 Marimo and the future of Jupyter notebooks
* 00:57:44 London's AI scene
Show Notes
* Pydantic
* Logfire
* Zod
* E2B
* Arize
* Marimo
* Prefect
* GLA (Google Generative Language API)
Transcript
Alessio [00:00:03]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.
Swyx [00:00:12]: Good morning. And today we're very excited to have Sam Colvin join us from Pydantic AI. Welcome. Sam, I heard that Pydantic is all we need. Is that true?
Samuel [00:00:24]: I would say you might need Pydantic AI and Logfire as well, but it gets you a long way, that's for sure.
Swyx [00:00:29]: Pydantic almost basically needs no introduction. It's almost 300 million downloads in December. And obviously, in the previous podcasts and discussions we've had with Jason Liu, he's been a big fan and promoter of Pydantic and AI.
Samuel [00:00:45]: Yeah, it's weird because obviously I didn't create Pydantic originally for uses in AI, it predates LLMs. But it's like we've been lucky that it's been picked up by that community and used so widely.
Swyx [00:00:58]: Actually, maybe we'll hear it. Right from you, what is Pydantic and maybe a little bit of the origin story?
Samuel [00:01:04]: The best name for it, which is not quite right, is a validation library. And we get some tension around that name because it doesn't just do validation, it will do coercion by default. We now have strict mode, so you can disable that coercion. But by default, if you say you want an integer field and you get in a string of 1, 2, 3, it will convert it to 123 and a bunch of other sensible conversions. And as you can imagine, the semantics around it. Exactly when you convert and when you don't, it's complicated, but because of that, it's more than just validation. Back in 2017, when I first started it, the different thing it was doing was using type hints to define your schema. That was controversial at the time. It was genuinely disapproved of by some people. I think the success of Pydantic and libraries like FastAPI that build on top of it means that today that's no longer controversial in Python. And indeed, lots of other people have copied that route, but yeah, it's a data validation library. It uses type hints for the for the most part and obviously does all the other stuff you want, like serialization on top of that. But yeah, that's the core.
Alessio [00:02:06]: Do you have any fun stories on how JSON schemas ended up being kind of like the structure output standard for LLMs? And were you involved in any of these discussions? Because I know OpenAI was, you know, one of the early adopters. So did they reach out to you? Was there kind of like a structure output console in open source that people were talking about or was it just a random?
Samuel [00:02:26]: No, very much not. So I originally. Didn't implement JSON schema inside Pydantic and then Sebastian, Sebastian Ramirez, FastAPI came along and like the first I ever heard of him was over a weekend. I got like 50 emails from him or 50 like emails as he was committing to Pydantic, adding JSON schema long pre version one. So the reason it was added was for OpenAPI, which is obviously closely akin to JSON schema. And then, yeah, I don't know why it was JSON that got picked up and used by OpenAI. It was obviously very convenient for us. That's because it meant that not only can you do the validation, but because Pydantic will generate you the JSON schema, it will it kind of can be one source of source of truth for structured outputs and tools.
Swyx [00:03:09]: Before we dive in further on the on the AI side of things, something I'm mildly curious about, obviously, there's Zod in JavaScript land. Every now and then there is a new sort of in vogue validation library that that takes over for quite a few years and then maybe like some something else comes along. Is Pydantic? Is it done like the core Pydantic?
Samuel [00:03:30]: I've just come off a call where we were redesigning some of the internal bits. There will be a v3 at some point, which will not break people's code half as much as v2 as in v2 was the was the massive rewrite into Rust, but also fixing all the stuff that was broken back from like version zero point something that we didn't fix in v1 because it was a side project. We have plans to move some of the basically store the data in Rust types after validation. Not completely. So we're still working to design the Pythonic version of it, in order for it to be able to convert into Python types. So then if you were doing like validation and then serialization, you would never have to go via a Python type we reckon that can give us somewhere between three and five times another three to five times speed up. That's probably the biggest thing. Also, like changing how easy it is to basically extend Pydantic and define how particular types, like for example, NumPy arrays are validated and serialized. But there's also stuff going on. And for example, Jitter, the JSON library in Rust that does the JSON parsing, has SIMD implementation at the moment only for AMD64. So we can add that. We need to go and add SIMD for other instruction sets. So there's a bunch more we can do on performance. I don't think we're going to go and revolutionize Pydantic, but it's going to continue to get faster, continue, hopefully, to allow people to do more advanced things. We might add a binary format like CBOR for serialization for when you'll just want to put the data into a database and probably load it again from Pydantic. So there are some things that will come along, but for the most part, it should just get faster and cleaner.
Alessio [00:05:04]: From a focus perspective, I guess, as a founder too, how did you think about the AI interest rising? And then how do you kind of prioritize, okay, this is worth going into more, and we'll talk about Pydantic AI and all of that. What was maybe your early experience with LLAMP, and when did you figure out, okay, this is something we should take seriously and focus more resources on it?
Samuel [00:05:28]: I'll answer that, but I'll answer what I think is a kind of parallel question, which is Pydantic's weird, because Pydantic existed, obviously, before I was starting a company. I was working on it in my spare time, and then beginning of 22, I started working on the rewrite in Rust. And I worked on it full-time for a year and a half, and then once we started the company, people came and joined. And it was a weird project, because that would never go away. You can't get signed off inside a startup. Like, we're going to go off and three engineers are going to work full-on for a year in Python and Rust, writing like 30,000 lines of Rust just to release open-source-free Python library. The result of that has been excellent for us as a company, right? As in, it's made us remain entirely relevant. And it's like, Pydantic is not just used in the SDKs of all of the AI libraries, but I can't say which one, but one of the big foundational model companies, when they upgraded from Pydantic v1 to v2, their number one internal model... The metric of performance is time to first token. That went down by 20%. So you think about all of the actual AI going on inside, and yet at least 20% of the CPU, or at least the latency inside requests was actually Pydantic, which shows like how widely it's used. So we've benefited from doing that work, although it didn't, it would have never have made financial sense in most companies. In answer to your question about like, how do we prioritize AI, I mean, the honest truth is we've spent a lot of the last year and a half building. Good general purpose observability inside LogFire and making Pydantic good for general purpose use cases. And the AI has kind of come to us. Like we just, not that we want to get away from it, but like the appetite, uh, both in Pydantic and in LogFire to go and build with AI is enormous because it kind of makes sense, right? Like if you're starting a new greenfield project in Python today, what's the chance that you're using GenAI 80%, let's say, globally, obviously it's like a hundred percent in California, but even worldwide, it's probably 80%. Yeah. And so everyone needs that stuff. And there's so much yet to be figured out so much like space to do things better in the ecosystem in a way that like to go and implement a database that's better than Postgres is a like Sisyphean task. Whereas building, uh, tools that are better for GenAI than some of the stuff that's about now is not very difficult. Putting the actual models themselves to one side.
Alessio [00:07:40]: And then at the same time, then you released Pydantic AI recently, which is, uh, um, you know, agent framework and early on, I would say everybody like, you know, Langchain and like, uh, Pydantic kind of like a first class support, a lot of these frameworks, we're trying to use you to be better. What was the decision behind we should do our own framework? Were there any design decisions that you disagree with any workloads that you think people didn't support? Well,
Samuel [00:08:05]: it wasn't so much like design and workflow, although I think there were some, some things we've done differently. Yeah. I think looking in general at the ecosystem of agent frameworks, the engineering quality is far below that of the rest of the Python ecosystem. There's a bunch of stuff that we have learned how to do over the last 20 years of building Python libraries and writing Python code that seems to be abandoned by people when they build agent frameworks. Now I can kind of respect that, particularly in the very first agent frameworks, like Langchain, where they were literally figuring out how to go and do this stuff. It's completely understandable that you would like basically skip some stuff.
Samuel [00:08:42]: I'm shocked by the like quality of some of the agent frameworks that have come out recently from like well-respected names, which it just seems to be opportunism and I have little time for that, but like the early ones, like I think they were just figuring out how to do stuff and just as lots of people have learned from Pydantic, we were able to learn a bit from them. I think from like the gap we saw and the thing we were frustrated by was the production readiness. And that means things like type checking, even if type checking makes it hard. Like Pydantic AI, I will put my hand up now and say it has a lot of generics and you need to, it's probably easier to use it if you've written a bit of Rust and you really understand generics, but like, and that is, we're not claiming that that makes it the easiest thing to use in all cases, we think it makes it good for production applications in big systems where type checking is a no-brainer in Python. But there are also a bunch of stuff we've learned from maintaining Pydantic over the years that we've gone and done. So every single example in Pydantic AI's documentation is run on Python. As part of tests and every single print output within an example is checked during tests. So it will always be up to date. And then a bunch of things that, like I say, are standard best practice within the rest of the Python ecosystem, but I'm not followed surprisingly by some AI libraries like coverage, linting, type checking, et cetera, et cetera, where I think these are no-brainers, but like weirdly they're not followed by some of the other libraries.
Alessio [00:10:04]: And can you just give an overview of the framework itself? I think there's kind of like the. LLM calling frameworks, there are the multi-agent frameworks, there's the workflow frameworks, like what does Pydantic AI do?
Samuel [00:10:17]: I glaze over a bit when I hear all of the different sorts of frameworks, but I like, and I will tell you when I built Pydantic, when I built Logfire and when I built Pydantic AI, my methodology is not to go and like research and review all of the other things. I kind of work out what I want and I go and build it and then feedback comes and we adjust. So the fundamental building block of Pydantic AI is agents. The exact definition of agents and how you want to define them. is obviously ambiguous and our things are probably sort of agent-lit, not that we would want to go and rename them to agent-lit, but like the point is you probably build them together to build something and most people will call an agent. So an agent in our case has, you know, things like a prompt, like system prompt and some tools and a structured return type if you want it, that covers the vast majority of cases. There are situations where you want to go further and the most complex workflows where you want graphs and I resisted graphs for quite a while. I was sort of of the opinion you didn't need them and you could use standard like Python flow control to do all of that stuff. I had a few arguments with people, but I basically came around to, yeah, I can totally see why graphs are useful. But then we have the problem that by default, they're not type safe because if you have a like add edge method where you give the names of two different edges, there's no type checking, right? Even if you go and do some, I'm not, not all the graph libraries are AI specific. So there's a, there's a graph library called, but it allows, it does like a basic runtime type checking. Ironically using Pydantic to try and make up for the fact that like fundamentally that graphs are not typed type safe. Well, I like Pydantic, but it did, that's not a real solution to have to go and run the code to see if it's safe. There's a reason that starting type checking is so powerful. And so we kind of, from a lot of iteration eventually came up with a system of using normally data classes to define nodes where you return the next node you want to call and where we're able to go and introspect the return type of a node to basically build the graph. And so the graph is. Yeah. Inherently type safe. And once we got that right, I, I wasn't, I'm incredibly excited about graphs. I think there's like masses of use cases for them, both in gen AI and other development, but also software's all going to have interact with gen AI, right? It's going to be like web. There's no longer be like a web department in a company is that there's just like all the developers are building for web building with databases. The same is going to be true for gen AI.
Alessio [00:12:33]: Yeah. I see on your docs, you call an agent, a container that contains a system prompt function. Tools, structure, result, dependency type model, and then model settings. Are the graphs in your mind, different agents? Are they different prompts for the same agent? What are like the structures in your mind?
Samuel [00:12:52]: So we were compelled enough by graphs once we got them right, that we actually merged the PR this morning. That means our agent implementation without changing its API at all is now actually a graph under the hood as it is built using our graph library. So graphs are basically a lower level tool that allow you to build these complex workflows. Our agents are technically one of the many graphs you could go and build. And we just happened to build that one for you because it's a very common, commonplace one. But obviously there are cases where you need more complex workflows where the current agent assumptions don't work. And that's where you can then go and use graphs to build more complex things.
Swyx [00:13:29]: You said you were cynical about graphs. What changed your mind specifically?
Samuel [00:13:33]: I guess people kept giving me examples of things that they wanted to use graphs for. And my like, yeah, but you could do that in standard flow control in Python became a like less and less compelling argument to me because I've maintained those systems that end up with like spaghetti code. And I could see the appeal of this like structured way of defining the workflow of my code. And it's really neat that like just from your code, just from your type hints, you can get out a mermaid diagram that defines exactly what can go and happen.
Swyx [00:14:00]: Right. Yeah. You do have very neat implementation of sort of inferring the graph from type hints, I guess. Yeah. Is what I would call it. Yeah. I think the question always is I have gone back and forth. I used to work at Temporal where we would actually spend a lot of time complaining about graph based workflow solutions like AWS step functions. And we would actually say that we were better because you could use normal control flow that you already knew and worked with. Yours, I guess, is like a little bit of a nice compromise. Like it looks like normal Pythonic code. But you just have to keep in mind what the type hints actually mean. And that's what we do with the quote unquote magic that the graph construction does.
Samuel [00:14:42]: Yeah, exactly. And if you look at the internal logic of actually running a graph, it's incredibly simple. It's basically call a node, get a node back, call that node, get a node back, call that node. If you get an end, you're done. We will add in soon support for, well, basically storage so that you can store the state between each node that's run. And then the idea is you can then distribute the graph and run it across computers. And also, I mean, the other weird, the other bit that's really valuable is across time. Because it's all very well if you look at like lots of the graph examples that like Claude will give you. If it gives you an example, it gives you this lovely enormous mermaid chart of like the workflow, for example, managing returns if you're an e-commerce company. But what you realize is some of those lines are literally one function calls another function. And some of those lines are wait six days for the customer to print their like piece of paper and put it in the post. And if you're writing like your demo. Project or your like proof of concept, that's fine because you can just say, and now we call this function. But when you're building when you're in real in real life, that doesn't work. And now how do we manage that concept to basically be able to start somewhere else in the in our code? Well, this graph implementation makes it incredibly easy because you just pass the node that is the start point for carrying on the graph and it continues to run. So it's things like that where I was like, yeah, I can just imagine how things I've done in the past would be fundamentally easier to understand if we had done them with graphs.
Swyx [00:16:07]: You say imagine, but like right now, this pedantic AI actually resume, you know, six days later, like you said, or is this just like a theoretical thing we can go someday?
Samuel [00:16:16]: I think it's basically Q&A. So there's an AI that's asking the user a question and effectively you then call the CLI again to continue the conversation. And it basically instantiates the node and calls the graph with that node again. Now, we don't have the logic yet for effectively storing state in the database between individual nodes that we're going to add soon. But like the rest of it is basically there.
Swyx [00:16:37]: It does make me think that not only are you competing with Langchain now and obviously Instructor, and now you're going into sort of the more like orchestrated things like Airflow, Prefect, Daxter, those guys.
Samuel [00:16:52]: Yeah, I mean, we're good friends with the Prefect guys and Temporal have the same investors as us. And I'm sure that my investor Bogomol would not be too happy if I was like, oh, yeah, by the way, as well as trying to take on Datadog. We're also going off and trying to take on Temporal and everyone else doing that. Obviously, we're not doing all of the infrastructure of deploying that right yet, at least. We're, you know, we're just building a Python library. And like what's crazy about our graph implementation is, sure, there's a bit of magic in like introspecting the return type, you know, extracting things from unions, stuff like that. But like the actual calls, as I say, is literally call a function and get back a thing and call that. It's like incredibly simple and therefore easy to maintain. The question is, how useful is it? Well, I don't know yet. I think we have to go and find out. We have a whole. We've had a slew of people joining our Slack over the last few days and saying, tell me how good Pydantic AI is. How good is Pydantic AI versus Langchain? And I refuse to answer. That's your job to go and find that out. Not mine. We built a thing. I'm compelled by it, but I'm obviously biased. The ecosystem will work out what the useful tools are.
Swyx [00:17:52]: Bogomol was my board member when I was at Temporal. And I think I think just generally also having been a workflow engine investor and participant in this space, it's a big space. Like everyone needs different functions. I think the one thing that I would say like yours, you know, as a library, you don't have that much control of it over the infrastructure. I do like the idea that each new agents or whatever or unit of work, whatever you call that should spin up in this sort of isolated boundaries. Whereas yours, I think around everything runs in the same process. But you ideally want to sort of spin out its own little container of things.
Samuel [00:18:30]: I agree with you a hundred percent. And we will. It would work now. Right. As in theory, you're just like as long as you can serialize the calls to the next node, you just have to all of the different containers basically have to have the same the same code. I mean, I'm super excited about Cloudflare workers running Python and being able to install dependencies. And if Cloudflare could only give me my invitation to the private beta of that, we would be exploring that right now because I'm super excited about that as a like compute level for some of this stuff where exactly what you're saying, basically. You can run everything as an individual. Like worker function and distribute it. And it's resilient to failure, et cetera, et cetera.
Swyx [00:19:08]: And it spins up like a thousand instances simultaneously. You know, you want it to be sort of truly serverless at once. Actually, I know we have some Cloudflare friends who are listening, so hopefully they'll get in front of the line. Especially.
Samuel [00:19:19]: I was in Cloudflare's office last week shouting at them about other things that frustrate me. I have a love-hate relationship with Cloudflare. Their tech is awesome. But because I use it the whole time, I then get frustrated. So, yeah, I'm sure I will. I will. I will get there soon.
Swyx [00:19:32]: There's a side tangent on Cloudflare. Is Python supported at full? I actually wasn't fully aware of what the status of that thing is.
Samuel [00:19:39]: Yeah. So Pyodide, which is Python running inside the browser in scripting, is supported now by Cloudflare. They basically, they're having some struggles working out how to manage, ironically, dependencies that have binaries, in particular, Pydantic. Because these workers where you can have thousands of them on a given metal machine, you don't want to have a difference. You basically want to be able to have a share. Shared memory for all the different Pydantic installations, effectively. That's the thing they work out. They're working out. But Hood, who's my friend, who is the primary maintainer of Pyodide, works for Cloudflare. And that's basically what he's doing, is working out how to get Python running on Cloudflare's network.
Swyx [00:20:19]: I mean, the nice thing is that your binary is really written in Rust, right? Yeah. Which also compiles the WebAssembly. Yeah. So maybe there's a way that you'd build... You have just a different build of Pydantic and that ships with whatever your distro for Cloudflare workers is.
Samuel [00:20:36]: Yes, that's exactly what... So Pyodide has builds for Pydantic Core and for things like NumPy and basically all of the popular binary libraries. Yeah. It's just basic. And you're doing exactly that, right? You're using Rust to compile the WebAssembly and then you're calling that shared library from Python. And it's unbelievably complicated, but it works. Okay.
Swyx [00:20:57]: Staying on graphs a little bit more, and then I wanted to go to some of the other features that you have in Pydantic AI. I see in your docs, there are sort of four levels of agents. There's single agents, there's agent delegation, programmatic agent handoff. That seems to be what OpenAI swarms would be like. And then the last one, graph-based control flow. Would you say that those are sort of the mental hierarchy of how these things go?
Samuel [00:21:21]: Yeah, roughly. Okay.
Swyx [00:21:22]: You had some expression around OpenAI swarms. Well.
Samuel [00:21:25]: And indeed, OpenAI have got in touch with me and basically, maybe I'm not supposed to say this, but basically said that Pydantic AI looks like what swarms would become if it was production ready. So, yeah. I mean, like, yeah, which makes sense. Awesome. Yeah. I mean, in fact, it was specifically saying, how can we give people the same feeling that they were getting from swarms that led us to go and implement graphs? Because my, like, just call the next agent with Python code was not a satisfactory answer to people. So it was like, okay, we've got to go and have a better answer for that. It's not like, let us to get to graphs. Yeah.
Swyx [00:21:56]: I mean, it's a minimal viable graph in some sense. What are the shapes of graphs that people should know? So the way that I would phrase this is I think Anthropic did a very good public service and also kind of surprisingly influential blog post, I would say, when they wrote Building Effective Agents. We actually have the authors coming to speak at my conference in New York, which I think you're giving a workshop at. Yeah.
Samuel [00:22:24]: I'm trying to work it out. But yes, I think so.
Swyx [00:22:26]: Tell me if you're not. yeah, I mean, like, that was the first, I think, authoritative view of, like, what kinds of graphs exist in agents and let's give each of them a name so that everyone is on the same page. So I'm just kind of curious if you have community names or top five patterns of graphs.
Samuel [00:22:44]: I don't have top five patterns of graphs. I would love to see what people are building with them. But like, it's been it's only been a couple of weeks. And of course, there's a point is that. Because they're relatively unopinionated about what you can go and do with them. They don't suit them. Like, you can go and do lots of lots of things with them, but they don't have the structure to go and have like specific names as much as perhaps like some other systems do. I think what our agents are, which have a name and I can't remember what it is, but this basically system of like, decide what tool to call, go back to the center, decide what tool to call, go back to the center and then exit. One form of graph, which, as I say, like our agents are effectively one implementation of a graph, which is why under the hood they are now using graphs. And it'll be interesting to see over the next few years whether we end up with these like predefined graph names or graph structures or whether it's just like, yep, I built a graph or whether graphs just turn out not to match people's mental image of what they want and die away. We'll see.
Swyx [00:23:38]: I think there is always appeal. Every developer eventually gets graph religion and goes, oh, yeah, everything's a graph. And then they probably over rotate and go go too far into graphs. And then they have to learn a whole bunch of DSLs. And then they're like, actually, I didn't need that. I need this. And they scale back a little bit.
Samuel [00:23:55]: I'm at the beginning of that process. I'm currently a graph maximalist, although I haven't actually put any into production yet. But yeah.
Swyx [00:24:02]: This has a lot of philosophical connections with other work coming out of UC Berkeley on compounding AI systems. I don't know if you know of or care. This is the Gartner world of things where they need some kind of industry terminology to sell it to enterprises. I don't know if you know about any of that.
Samuel [00:24:24]: I haven't. I probably should. I should probably do it because I should probably get better at selling to enterprises. But no, no, I don't. Not right now.
Swyx [00:24:29]: This is really the argument is that instead of putting everything in one model, you have more control and more maybe observability to if you break everything out into composing little models and changing them together. And obviously, then you need an orchestration framework to do that. Yeah.
Samuel [00:24:47]: And it makes complete sense. And one of the things we've seen with agents is they work well when they work well. But when they. Even if you have the observability through log five that you can see what was going on, if you don't have a nice hook point to say, hang on, this is all gone wrong. You have a relatively blunt instrument of basically erroring when you exceed some kind of limit. But like what you need to be able to do is effectively iterate through these runs so that you can have your own control flow where you're like, OK, we've gone too far. And that's where one of the neat things about our graph implementation is you can basically call next in a loop rather than just running the full graph. And therefore, you have this opportunity to to break out of it. But yeah, basically, it's the same point, which is like if you have two bigger unit of work to some extent, whether or not it involves gen AI. But obviously, it's particularly problematic in gen AI. You only find out afterwards when you've spent quite a lot of time and or money when it's gone off and done done the wrong thing.
Swyx [00:25:39]: Oh, drop on this. We're not going to resolve this here, but I'll drop this and then we can move on to the next thing. This is the common way that we we developers talk about this. And then the machine learning researchers look at us. And laugh and say, that's cute. And then they just train a bigger model and they wipe us out in the next training run. So I think there's a certain amount of we are fighting the bitter lesson here. We're fighting AGI. And, you know, when AGI arrives, this will all go away. Obviously, on Latent Space, we don't really discuss that because I think AGI is kind of this hand wavy concept that isn't super relevant. But I think we have to respect that. For example, you could do a chain of thoughts with graphs and you could manually orchestrate a nice little graph that does like. Reflect, think about if you need more, more inference time, compute, you know, that's the hot term now. And then think again and, you know, scale that up. Or you could train Strawberry and DeepSeq R1. Right.
Samuel [00:26:32]: I saw someone saying recently, oh, they were really optimistic about agents because models are getting faster exponentially. And I like took a certain amount of self-control not to describe that it wasn't exponential. But my main point was. If models are getting faster as quickly as you say they are, then we don't need agents and we don't really need any of these abstraction layers. We can just give our model and, you know, access to the Internet, cross our fingers and hope for the best. Agents, agent frameworks, graphs, all of this stuff is basically making up for the fact that right now the models are not that clever. In the same way that if you're running a customer service business and you have loads of people sitting answering telephones, the less well trained they are, the less that you trust them, the more that you need to give them a script to go through. Whereas, you know, so if you're running a bank and you have lots of customer service people who you don't trust that much, then you tell them exactly what to say. If you're doing high net worth banking, you just employ people who you think are going to be charming to other rich people and set them off to go and have coffee with people. Right. And the same is true of models. The more intelligent they are, the less we need to tell them, like structure what they go and do and constrain the routes in which they take.
Swyx [00:27:42]: Yeah. Yeah. Agree with that. So I'm happy to move on. So the other parts of Pydantic AI that are worth commenting on, and this is like my last rant, I promise. So obviously, every framework needs to do its sort of model adapter layer, which is, oh, you can easily swap from OpenAI to Cloud to Grok. You also have, which I didn't know about, Google GLA, which I didn't really know about until I saw this in your docs, which is generative language API. I assume that's AI Studio? Yes.
Samuel [00:28:13]: Google don't have good names for it. So Vertex is very clear. That seems to be the API that like some of the things use, although it returns 503 about 20% of the time. So... Vertex? No. Vertex, fine. But the... Oh, oh. GLA. Yeah. Yeah.
Swyx [00:28:28]: I agree with that.
Samuel [00:28:29]: So we have, again, another example of like, well, I think we go the extra mile in terms of engineering is we run on every commit, at least commit to main, we run tests against the live models. Not lots of tests, but like a handful of them. Oh, okay. And we had a point last week where, yeah, GLA is a little bit better. GLA1 was failing every single run. One of their tests would fail. And we, I think we might even have commented out that one at the moment. So like all of the models fail more often than you might expect, but like that one seems to be particularly likely to fail. But Vertex is the same API, but much more reliable.
Swyx [00:29:01]: My rant here is that, you know, versions of this appear in Langchain and every single framework has to have its own little thing, a version of that. I would put to you, and then, you know, this is, this can be agree to disagree. This is not needed in Pydantic AI. I would much rather you adopt a layer like Lite LLM or what's the other one in JavaScript port key. And that's their job. They focus on that one thing and they, they normalize APIs for you. All new models are automatically added and you don't have to duplicate this inside of your framework. So for example, if I wanted to use deep seek, I'm out of luck because Pydantic AI doesn't have deep seek yet.
Samuel [00:29:38]: Yeah, it does.
Swyx [00:29:39]: Oh, it does. Okay. I'm sorry. But you know what I mean? Should this live in your code or should it live in a layer that's kind of your API gateway that's a defined piece of infrastructure that people have?
Samuel [00:29:49]: And I think if a company who are well known, who are respected by everyone had come along and done this at the right time, maybe we should have done it a year and a half ago and said, we're going to be the universal AI layer. That would have been a credible thing to do. I've heard varying reports of Lite LLM is the truth. And it didn't seem to have exactly the type safety that we needed. Also, as I understand it, and again, I haven't looked into it in great detail. Part of their business model is proxying the request through their, through their own system to do the generalization. That would be an enormous put off to an awful lot of people. Honestly, the truth is I don't think it is that much work unifying the model. I get where you're coming from. I kind of see your point. I think the truth is that everyone is centralizing around open AIs. Open AI's API is the one to do. So DeepSeq support that. Grok with OK support that. Ollama also does it. I mean, if there is that library right now, it's more or less the open AI SDK. And it's very high quality. It's well type checked. It uses Pydantic. So I'm biased. But I mean, I think it's pretty well respected anyway.
Swyx [00:30:57]: There's different ways to do this. Because also, it's not just about normalizing the APIs. You have to do secret management and all that stuff.
Samuel [00:31:05]: Yeah. And there's also. There's Vertex and Bedrock, which to one extent or another, effectively, they host multiple models, but they don't unify the API. But they do unify the auth, as I understand it. Although we're halfway through doing Bedrock. So I don't know about it that well. But they're kind of weird hybrids because they support multiple models. But like I say, the auth is centralized.
Swyx [00:31:28]: Yeah, I'm surprised they don't unify the API. That seems like something that I would do. You know, we can discuss all this all day. There's a lot of APIs. I agree.
Samuel [00:31:36]: It would be nice if there was a universal one that we didn't have to go and build.
Alessio [00:31:39]: And I guess the other side of, you know, routing model and picking models like evals. How do you actually figure out which one you should be using? I know you have one. First of all, you have very good support for mocking in unit tests, which is something that a lot of other frameworks don't do. So, you know, my favorite Ruby library is VCR because it just, you know, it just lets me store the HTTP requests and replay them. That part I'll kind of skip. I think you are busy like this test model. We're like just through Python. You try and figure out what the model might respond without actually calling the model. And then you have the function model where people can kind of customize outputs. Any other fun stories maybe from there? Or is it just what you see is what you get, so to speak?
Samuel [00:32:18]: On those two, I think what you see is what you get. On the evals, I think watch this space. I think it's something that like, again, I was somewhat cynical about for some time. Still have my cynicism about some of the well, it's unfortunate that so many different things are called evals. It would be nice if we could agree. What they are and what they're not. But look, I think it's a really important space. I think it's something that we're going to be working on soon, both in Pydantic AI and in LogFire to try and support better because it's like it's an unsolved problem.
Alessio [00:32:45]: Yeah, you do say in your doc that anyone who claims to know for sure exactly how your eval should be defined can safely be ignored.
Samuel [00:32:52]: We'll delete that sentence when we tell people how to do their evals.
Alessio [00:32:56]: Exactly. I was like, we need we need a snapshot of this today. And so let's talk about eval. So there's kind of like the vibe. Yeah. So you have evals, which is what you do when you're building. Right. Because you cannot really like test it that many times to get statistical significance. And then there's the production eval. So you also have LogFire, which is kind of like your observability product, which I tried before. It's very nice. What are some of the learnings you've had from building an observability tool for LEMPs? And yeah, as people think about evals, even like what are the right things to measure? What are like the right number of samples that you need to actually start making decisions?
Samuel [00:33:33]: I'm not the best person to answer that is the truth. So I'm not going to come in here and tell you that I think I know the answer on the exact number. I mean, we can do some back of the envelope statistics calculations to work out that like having 30 probably gets you most of the statistical value of having 200 for, you know, by definition, 15% of the work. But the exact like how many examples do you need? For example, that's a much harder question to answer because it's, you know, it's deep within the how models operate in terms of LogFire. One of the reasons we built LogFire the way we have and we allow you to write SQL directly against your data and we're trying to build the like powerful fundamentals of observability is precisely because we know we don't know the answers. And so allowing people to go and innovate on how they're going to consume that stuff and how they're going to process it is we think that's valuable. Because even if we come along and offer you an evals framework on top of LogFire, it won't be right in all regards. And we want people to be able to go and innovate and being able to write their own SQL connected to the API. And effectively query the data like it's a database with SQL allows people to innovate on that stuff. And that's what allows us to do it as well. I mean, we do a bunch of like testing what's possible by basically writing SQL directly against LogFire as any user could. I think the other the other really interesting bit that's going on in observability is OpenTelemetry is centralizing around semantic attributes for GenAI. So it's a relatively new project. A lot of it's still being added at the moment. But basically the idea that like. They unify how both SDKs and or agent frameworks send observability data to to any OpenTelemetry endpoint. And so, again, we can go and having that unification allows us to go and like basically compare different libraries, compare different models much better. That stuff's in a very like early stage of development. One of the things we're going to be working on pretty soon is basically, I suspect, GenAI will be the first agent framework that implements those semantic attributes properly. Because, again, we control and we can say this is important for observability, whereas most of the other agent frameworks are not maintained by people who are trying to do observability. With the exception of Langchain, where they have the observability platform, but they chose not to go down the OpenTelemetry route. So they're like plowing their own furrow. And, you know, they're a lot they're even further away from standardization.
Alessio [00:35:51]: Can you maybe just give a quick overview of how OTEL ties into the AI workflows? There's kind of like the question of is, you know, a trace. And a span like a LLM call. Is it the agent? It's kind of like the broader thing you're tracking. How should people think about it?
Samuel [00:36:06]: Yeah, so they have a PR that I think may have now been merged from someone at IBM talking about remote agents and trying to support this concept of remote agents within GenAI. I'm not particularly compelled by that because I don't think that like that's actually by any means the common use case. But like, I suppose it's fine for it to be there. The majority of the stuff in OTEL is basically defining how you would instrument. A given call to an LLM. So basically the actual LLM call, what data you would send to your telemetry provider, how you would structure that. Apart from this slightly odd stuff on remote agents, most of the like agent level consideration is not yet implemented in is not yet decided effectively. And so there's a bit of ambiguity. Obviously, what's good about OTEL is you can in the end send whatever attributes you like. But yeah, there's quite a lot of churn in that space and exactly how we store the data. I think that one of the most interesting things, though, is that if you think about observability. Traditionally, it was sure everyone would say our observability data is very important. We must keep it safe. But actually, companies work very hard to basically not have anything that sensitive in their observability data. So if you're a doctor in a hospital and you search for a drug for an STI, the sequel might be sent to the observability provider. But none of the parameters would. It wouldn't have the patient number or their name or the drug. With GenAI, that distinction doesn't exist because it's all just messed up in the text. If you have that same patient asking an LLM how to. What drug they should take or how to stop smoking. You can't extract the PII and not send it to the observability platform. So the sensitivity of the data that's going to end up in observability platforms is going to be like basically different order of magnitude to what's in what you would normally send to Datadog. Of course, you can make a mistake and send someone's password or their card number to Datadog. But that would be seen as a as a like mistake. Whereas in GenAI, a lot of data is going to be sent. And I think that's why companies like Langsmith and are trying hard to offer observability. On prem, because there's a bunch of companies who are happy for Datadog to be cloud hosted, but want self-hosted self-hosting for this observability stuff with GenAI.
Alessio [00:38:09]: And are you doing any of that today? Because I know in each of the spans you have like the number of tokens, you have the context, you're just storing everything. And then you're going to offer kind of like a self-hosting for the platform, basically. Yeah. Yeah.
Samuel [00:38:23]: So we have scrubbing roughly equivalent to what the other observability platforms have. So if we, you know, if we see password as the key, we won't send the value. But like, like I said, that doesn't really work in GenAI. So we're accepting we're going to have to store a lot of data and then we'll offer self-hosting for those people who can afford it and who need it.
Alessio [00:38:42]: And then this is, I think, the first time that most of the workloads performance is depending on a third party. You know, like if you're looking at Datadog data, usually it's your app that is driving the latency and like the memory usage and all of that. Here you're going to have spans that maybe take a long time to perform because the GLA API is not working or because OpenAI is kind of like overwhelmed. Do you do anything there since like the provider is almost like the same across customers? You know, like, are you trying to surface these things for people and say, hey, this was like a very slow span, but actually all customers using OpenAI right now are seeing the same thing. So maybe don't worry about it or.
Samuel [00:39:20]: Not yet. We do a few things that people don't generally do in OTA. So we send. We send information at the beginning. At the beginning of a trace as well as sorry, at the beginning of a span, as well as when it finishes. By default, OTA only sends you data when the span finishes. So if you think about a request which might take like 20 seconds, even if some of the intermediate spans finished earlier, you can't basically place them on the page until you get the top level span. And so if you're using standard OTA, you can't show anything until those requests are finished. When those requests are taking a few hundred milliseconds, it doesn't really matter. But when you're doing Gen AI calls or when you're like running a batch job that might take 30 minutes. That like latency of not being able to see the span is like crippling to understanding your application. And so we've we do a bunch of slightly complex stuff to basically send data about a span as it starts, which is closely related. Yeah.
Alessio [00:40:09]: Any thoughts on all the other people trying to build on top of OpenTelemetry in different languages, too? There's like the OpenLEmetry project, which doesn't really roll off the tongue. But how do you see the future of these kind of tools? Is everybody going to have to build? Why does everybody want to build? They want to build their own open source observability thing to then sell?
Samuel [00:40:29]: I mean, we are not going off and trying to instrument the likes of the OpenAI SDK with the new semantic attributes, because at some point that's going to happen and it's going to live inside OTEL and we might help with it. But we're a tiny team. We don't have time to go and do all of that work. So OpenLEmetry, like interesting project. But I suspect eventually most of those semantic like that instrumentation of the big of the SDKs will live, like I say, inside the main OpenTelemetry report. I suppose. What happens to the agent frameworks? What data you basically need at the framework level to get the context is kind of unclear. I don't think we know the answer yet. But I mean, I was on the, I guess this is kind of semi-public, because I was on the call with the OpenTelemetry call last week talking about GenAI. And there was someone from Arize talking about the challenges they have trying to get OpenTelemetry data out of Langchain, where it's not like natively implemented. And obviously they're having quite a tough time. And I was realizing, hadn't really realized this before, but how lucky we are to primarily be talking about our own agent framework, where we have the control rather than trying to go and instrument other people's.
Swyx [00:41:36]: Sorry, I actually didn't know about this semantic conventions thing. It looks like, yeah, it's merged into main OTel. What should people know about this? I had never heard of it before.
Samuel [00:41:45]: Yeah, I think it looks like a great start. I think there's some unknowns around how you send the messages that go back and forth, which is kind of the most important part. It's the most important thing of all. And that is moved out of attributes and into OTel events. OTel events in turn are moving from being on a span to being their own top-level API where you send data. So there's a bunch of churn still going on. I'm impressed by how fast the OTel community is moving on this project. I guess they, like everyone else, get that this is important, and it's something that people are crying out to get instrumentation off. So I'm kind of pleasantly surprised at how fast they're moving, but it makes sense.
Swyx [00:42:25]: I'm just kind of browsing through the specification. I can already see that this basically bakes in whatever the previous paradigm was. So now they have genai.usage.prompt tokens and genai.usage.completion tokens. And obviously now we have reasoning tokens as well. And then only one form of sampling, which is top-p. You're basically baking in or sort of reifying things that you think are important today, but it's not a super foolproof way of doing this for the future. Yeah.
Samuel [00:42:54]: I mean, that's what's neat about OTel is you can always go and send another attribute and that's fine. It's just there are a bunch that are agreed on. But I would say, you know, to come back to your previous point about whether or not we should be relying on one centralized abstraction layer, this stuff is moving so fast that if you start relying on someone else's standard, you risk basically falling behind because you're relying on someone else to keep things up to date.
Swyx [00:43:14]: Or you fall behind because you've got other things going on.
Samuel [00:43:17]: Yeah, yeah. That's fair. That's fair.
Swyx [00:43:19]: Any other observations just about building LogFire, actually? Let's just talk about this. So you announced LogFire. I was kind of only familiar with LogFire because of your Series A announcement. I actually thought you were making a separate company. I remember some amount of confusion with you when that came out. So to be clear, it's Pydantic LogFire and the company is one company that has kind of two products, an open source thing and an observability thing, correct? Yeah. I was just kind of curious, like any learnings building LogFire? So classic question is, do you use ClickHouse? Is this like the standard persistence layer? Any learnings doing that?
Samuel [00:43:54]: We don't use ClickHouse. We started building our database with ClickHouse, moved off ClickHouse onto Timescale, which is a Postgres extension to do analytical databases. Wow. And then moved off Timescale onto DataFusion. And we're basically now building, it's DataFusion, but it's kind of our own database. Bogomil is not entirely happy that we went through three databases before we chose one. I'll say that. But like, we've got to the right one in the end. I think we could have realized that Timescale wasn't right. I think ClickHouse. They both taught us a lot and we're in a great place now. But like, yeah, it's been a real journey on the database in particular.
Swyx [00:44:28]: Okay. So, you know, as a database nerd, I have to like double click on this, right? So ClickHouse is supposed to be the ideal backend for anything like this. And then moving from ClickHouse to Timescale is another counterintuitive move that I didn't expect because, you know, Timescale is like an extension on top of Postgres. Not super meant for like high volume logging. But like, yeah, tell us those decisions.
Samuel [00:44:50]: So at the time, ClickHouse did not have good support for JSON. I was speaking to someone yesterday and said ClickHouse doesn't have good support for JSON and got roundly stepped on because apparently it does now. So they've obviously gone and built their proper JSON support. But like back when we were trying to use it, I guess a year ago or a bit more than a year ago, everything happened to be a map and maps are a pain to try and do like looking up JSON type data. And obviously all these attributes, everything you're talking about there in terms of the GenAI stuff. You can choose to make them top level columns if you want. But the simplest thing is just to put them all into a big JSON pile. And that was a problem with ClickHouse. Also, ClickHouse had some really ugly edge cases like by default, or at least until I complained about it a lot, ClickHouse thought that two nanoseconds was longer than one second because they compared intervals just by the number, not the unit. And I complained about that a lot. And then they caused it to raise an error and just say you have to have the same unit. Then I complained a bit more. And I think as I understand it now, they have some. They convert between units. But like stuff like that, when all you're looking at is when a lot of what you're doing is comparing the duration of spans was really painful. Also things like you can't subtract two date times to get an interval. You have to use the date sub function. But like the fundamental thing is because we want our end users to write SQL, the like quality of the SQL, how easy it is to write, matters way more to us than if you're building like a platform on top where your developers are going to write the SQL. And once it's written and it's working, you don't mind too much. So I think that's like one of the fundamental differences. The other problem that I have with the ClickHouse and Impact Timescale is that like the ultimate architecture, the like snowflake architecture of binary data in object store queried with some kind of cache from nearby. They both have it, but it's closed sourced and you only get it if you go and use their hosted versions. And so even if we had got through all the problems with Timescale or ClickHouse, we would end up like, you know, they would want to be taking their 80% margin. And then we would be wanting to take that would basically leave us less space for margin. Whereas data fusion. Properly open source, all of that same tooling is open source. And for us as a team of people with a lot of Rust expertise, data fusion, which is implemented in Rust, we can literally dive into it and go and change it. So, for example, I found that there were some slowdowns in data fusion's string comparison kernel for doing like string contains. And it's just Rust code. And I could go and rewrite the string comparison kernel to be faster. Or, for example, data fusion, when we started using it, didn't have JSON support. Obviously, as I've said, it's something we can do. It's something we needed. I was able to go and implement that in a weekend using our JSON parser that we built for Pydantic Core. So it's the fact that like data fusion is like for us the perfect mixture of a toolbox to build a database with, not a database. And we can go and implement stuff on top of it in a way that like if you were trying to do that in Postgres or in ClickHouse. I mean, ClickHouse would be easier because it's C++, relatively modern C++. But like as a team of people who are not C++ experts, that's much scarier than data fusion for us.
Swyx [00:47:47]: Yeah, that's a beautiful rant.
Alessio [00:47:49]: That's funny. Most people don't think they have agency on these projects. They're kind of like, oh, I should use this or I should use that. They're not really like, what should I pick so that I contribute the most back to it? You know, so but I think you obviously have an open source first mindset. So that makes a lot of sense.
Samuel [00:48:05]: I think if we were probably better as a startup, a better startup and faster moving and just like headlong determined to get in front of customers as fast as possible, we should have just started with ClickHouse. I hope that long term we're in a better place for having worked with data fusion. We like we're quite engaged now with the data fusion community. Andrew Lam, who maintains data fusion, is an advisor to us. We're in a really good place now. But yeah, it's definitely slowed us down relative to just like building on ClickHouse and moving as fast as we can.
Swyx [00:48:34]: OK, we're about to zoom out and do Pydantic run and all the other stuff. But, you know, my last question on LogFire is really, you know, at some point you run out sort of community goodwill just because like, oh, I use Pydantic. I love Pydantic. I'm going to use LogFire. OK, then you start entering the territory of the Datadogs, the Sentrys and the honeycombs. Yeah. So where are you going to really spike here? What differentiator here?
Samuel [00:48:59]: I wasn't writing code in 2001, but I'm assuming that there were people talking about like web observability and then web observability stopped being a thing, not because the web stopped being a thing, but because all observability had to do web. If you were talking to people in 2010 or 2012, they would have talked about cloud observability. Now that's not a term because all observability is cloud first. The same is going to happen to gen AI. And so whether or not you're trying to compete with Datadog or with Arise and Langsmith, you've got to do first class. You've got to do general purpose observability with first class support for AI. And as far as I know, we're the only people really trying to do that. I mean, I think Datadog is starting in that direction. And to be honest, I think Datadog is a much like scarier company to compete with than the AI specific observability platforms. Because in my opinion, and I've also heard this from lots of customers, AI specific observability where you don't see everything else going on in your app is not actually that useful. Our hope is that we can build the first general purpose observability platform with first class support for AI. And that we have this open source heritage of putting developer experience first that other companies haven't done. For all I'm a fan of Datadog and what they've done. If you search Datadog logging Python. And you just try as a like a non-observability expert to get something up and running with Datadog and Python. It's not trivial, right? That's something Sentry have done amazingly well. But like there's enormous space in most of observability to do DX better.
Alessio [00:50:27]: Since you mentioned Sentry, I'm curious how you thought about licensing and all of that. Obviously, your MIT license, you don't have any rolling license like Sentry has where you can only use an open source, like the one year old version of it. Was that a hard decision?
Samuel [00:50:41]: So to be clear, LogFire is co-sourced. So Pydantic and Pydantic AI are MIT licensed and like properly open source. And then LogFire for now is completely closed source. And in fact, the struggles that Sentry have had with licensing and the like weird pushback the community gives when they take something that's closed source and make it source available just meant that we just avoided that whole subject matter. I think the other way to look at it is like in terms of either headcount or revenue or dollars in the bank. The amount of open source we do as a company is we've got to be open source. We're up there with the most prolific open source companies, like I say, per head. And so we didn't feel like we were morally obligated to make LogFire open source. We have Pydantic. Pydantic is a foundational library in Python. That and now Pydantic AI are our contribution to open source. And then LogFire is like openly for profit, right? As in we're not claiming otherwise. We're not sort of trying to walk a line if it's open source. But really, we want to make it hard to deploy. So you probably want to pay us. We're trying to be straight. That it's to pay for. We could change that at some point in the future, but it's not an immediate plan.
Alessio [00:51:48]: All right. So the first one I saw this new I don't know if it's like a product you're building the Pydantic that run, which is a Python browser sandbox. What was the inspiration behind that? We talk a lot about code interpreter for lamps. I'm an investor in a company called E2B, which is a code sandbox as a service for remote execution. Yeah. What's the Pydantic that run story?
Samuel [00:52:09]: So Pydantic that run is again completely open source. I have no interest in making it into a product. We just needed a sandbox to be able to demo LogFire in particular, but also Pydantic AI. So it doesn't have it yet, but I'm going to add basically a proxy to OpenAI and the other models so that you can run Pydantic AI in the browser. See how it works. Tweak the prompt, et cetera, et cetera. And we'll have some kind of limit per day of what you can spend on it or like what the spend is. The other thing we wanted to be able to do was to be able to when you log into LogFire. We have quite a lot of drop off of like a lot of people sign up, find it interesting and then don't go and create a project. And my intuition is that they're like, oh, OK, cool. But now I have to go and open up my development environment, create a new project, do something with the right token. I can't be bothered. And then they drop off and they forget to come back. And so we wanted a really nice way of being able to click here and you can run it in the browser and see what it does. As I think happens to all of us, I sort of started seeing if I could do it a week and a half ago. Got something to run. And then ended up, you know, improving it. And suddenly I spent a week on it. But I think it's useful. Yeah.
Alessio [00:53:15]: I remember maybe a couple, two, three years ago, there were a couple of companies trying to build in the browser terminals exactly for this. It's like, you know, you go on GitHub, you see a project that is interesting, but now you got to like clone it and run it on your machine. Sometimes it can be sketchy. This is cool, especially since you already make all the docs runnable in your docs. Like you said, you kind of test them. It sounds like you might just have.
Samuel [00:53:39]: So, yeah. The thing is that on every example in Pydantic AI, there's a button that basically says run, which takes you into Pydantic.run, has that code there. And depending on how hard we want to push, we can also have it like hooked up to LogFire automatically. So there's a like, hey, just come and join the project. And you can see what that looks like in LogFire.
Swyx [00:53:58]: That's super cool.
Alessio [00:53:59]: So I think that's one of the biggest personally for me, one of the biggest drop offs from open source projects. It's kind of like do this. And then as long as something as soon as something doesn't work, I just drop off.
Swyx [00:54:09]: So it takes some discipline. You know, like there's been very many versions of this that I've been through in my career where you had to extract this code and run it. And it always falls out of date. Often we would have these this concept of transclusion where we have a separate code examples repo that we want to be that and that we pulled into our docs. And it never never really works. It takes a lot of discipline. So kudos to you on this.
Samuel [00:54:31]: And it was it was years of maintaining Pydantic and people complaining, hey, that example is out of date now. But eventually we went and built a PyTest example. Which is another the hardest to search for open source project we ever built. Because obviously, as you can imagine, if you search PyTest examples, you get examples of how to use PyTest. But the PyTest examples will basically go through both your code inside your doc strings to look for Python code and through markdown in your docs and extract that code and then run it for you and run linting over it and soon run type checking over it. So and that's how we keep our examples up to date. But now now we have these like hundreds of examples. All of which are runnable and self-contained. Or if they if they refer to the previous example, it's already structured that they have to be able to import the code from the previous example. So why don't we give someone a nice place to just be able to actually run that using OpenAI and see what the output is. Lovely.
Alessio [00:55:24]: All right. So that's kind of Pydantic. And the notes here, I just like going through people's X account, not Twitter. So for four years, you've been saying we need a plain text accessor to Jupyter notebooks. Yeah. I think people maybe have gone the other way, which may get even more opinionated, like with X and like all these kind of like notebook companies.
Samuel [00:55:46]: Well, yes. So in reply to that, someone replied and said Marimo is that. And sure enough, Marimo is really impressive. And I've subsequently spoken to spoken to the Marimo guys and got to angel invest in their account. I think it's SeedGround. So like Marimo is very cool. It's doing that. And Marimo also notebooks also run in the browser again using Pyodide. In fact, I nearly got there. We didn't build Pydantic.run because we were just going to use Marimo. But my concern was that people would think LogFire was only to be used in notebooks. And I wanted something that like ironically felt more basic, felt more like a terminal so that no one thought it was like just for notebooks. Yeah.
Swyx [00:56:22]: There's a lot of notebook haters out there.
Samuel [00:56:24]: And indeed, I have very strong opinions about, you know, proper like Jupyter notebooks. This idea that like you have to run the cells in the right order. I mean, a whole bunch of things. It's basically like worse than Excel or similar. Similarly bad to Excel. Oh, so you are a notebook hater that invested in a notebook. I have this rant called notebook, which was like my attempt to build an alternative that is mostly just a rant about the 10 reasons why notebooks are just as bad as Excel. But Marimo et al, the new ones that are text-based, at least solve a whole bunch of those problems.
Swyx [00:56:58]: Agree with that. Yes. I was kind of wishing for something like a better notebook. And then I saw Marimo. I was like, oh, yeah, these guys have are ahead of me on this. Yeah. I don't know if I would do the sort of annotation-based thing. Like, you know, a lot of people love the, oh, annotate this function. And it just adds magic. I think similarly to what Jeremy Howard does with his stuff. It seems a little bit too magical still. But hey, it's a big improvement from notebooks. Yeah.
Samuel [00:57:23]: Yeah. Great.
Alessio [00:57:24]: Just as on the LLM usage, like the IPyMB file, it's just not good to put in LLMs. So just that alone, I think should be okay.
Swyx [00:57:36]: It's just not good to put in LLMs.
Alessio [00:57:38]: It's really not. They freak out.
Samuel [00:57:41]: It's not good to put in Git either. I mean, I freak out.
Swyx [00:57:44]: Okay. Well, we will kill IPyMB at some point. Yeah. Any other takes? I was going to ask you just like, broaden out just about the London scene. You know, what's it like building out there, you know, over the pond?
Samuel [00:57:56]: I'm an evening person. And the good thing is that I can get up late and then work late because I'm speaking to people in the U.S. a lot of the time. So I got invited just earlier today to some drinks reception.
Samuel [00:58:09]: So I'm feeling positive about the U.K. right now on AI. But I think, look, like everywhere that isn't the U.S. and China knows that we're like way behind on AI. I think it's good that the U.K. is like beginning to say, this is an opportunity, not just a risk. I keep being told you should be at more events. You should be like, you know, hanging out with AI people more. My instinct is like, I'd rather sit at my computer and write code. I think that like, is probably a more effective way of getting people's attention. I'm like, I don't know. I mean, like a bit of me thinks I should be sitting on Twitter, not in San Francisco chatting to people. I think it's probably a bit of a mixture and I could probably do with being in the States a bit more. I think I'm going to be over there a bit more this year. But like, there's definitely the risk if you're in somewhere where everyone wants to chat to you about code where you don't write any code. And that's a failure mode.
Swyx [00:58:58]: I would say, yeah, definitely for sure. There's a scene and, you know, one way to really fail at this is to just be involved in that scene. And have that eat up your time, but be at the right events and the ones that I'm running are good events, hopefully.
Swyx [00:59:16]: What I say is like, use those things to produce high quality content that travels in a different medium than you normally would be able to. Because there's some selectivity, because there's a broad, there's a focused community on that thing. They will discover your work more. It will be highly produced, you know, that's the pitch over there on why at least I do conferences. And then in terms of talking to people, I always think about this, a three strikes rule. So after a while it gets repetitive, but maybe like the first 10, 20 conversations you have about people, if the same stuff is coming up, that is an indication to you that people like want a thing and it helps you prioritize in a more long form way than you can get in shallow interactions online, right? So that in person, eye to eye, like this is my pain at work and you see the pain and you're like, oh, okay. Like if I do this for you. You will love our tool and like, you can't really replace that. It's customer interviews. Really. Yeah.
Samuel [01:00:11]: I agree entirely with that. I think that I think there's a, you're, you're right on a lot of that. And I think that like, it's very easy to get distracted by what people are saying on Twitter and LinkedIn.
Swyx [01:00:19]: That's another thing.
Samuel [01:00:20]: It's pretty hard to correct for which of those people are actually building this stuff in production in like serious companies and which of them are on day four of learning to code. Cause they have equally strident opinions and in like few characters, they, they seem equally valid. But which one's real and which one's not, or which one is from someone who really knows their stuff is, is hard to know.
Alessio [01:00:40]: Anything else, Sam? What do you want to get off your chest?
Samuel [01:00:43]: Nothing in particular. I think we, I've really enjoyed our conversation. I would say, I think if anyone who is like looked at, at Pydance AI, we know it's not complete yet. We know there's a bunch of things that are missing embeddings, like storage, MCP and tool sets and stuff like that. We're trying to be deliberate and do stuff well. And that involves not being feature complete yet. Like keep coming back and looking in a few months because we're, we're pretty determined to get that. We know that this stuff is like, whether or not you think that AI is going to be the next Excel, the next internet or the next industrial revolution is going to affect all of us enormously. And so as a company, we get that like making Pydantic AI the best agent framework is existential for us.
Alessio [01:01:22]: You're also the first series A company I see that has no open roles for now. Every founder that comes in our podcast, the call to action is like, please come work with us.
Samuel [01:01:31]: We are not hiring right now. I want to, I would love, uh, bluntly for Logfire to have a bit more commercial traction and a bit more revenue before I, before I hire some more people. It's quite nice having a few years of runway, not a few months of runway. So I'm not in any, any great appetite to go and like destroy that runway overnight by hiring another, another 10 people. Even if like we, the whole team is like rushed off their feet, kind of doing, as you said, like three to four startups at the same time.
Alessio [01:01:58]: Awesome, man. Thank you for joining us.
Samuel [01:01:59]: Thank you very much.
Get full access to Latent.Space at www.latent.space/subscribe
E171: How Companies Like Block Build Viral Open Source Projects
Open Source Startup Podcast •

Manik Surtani is Head of Open Source and Bradley Axen is Principal Engineer at Block. Manik was key to launching Block's Open Source Programs Office and Bradley is a major open source contributor - including the project Goose which is Block's extensible AI agent project. It currently has over 11K stars on GitHub and has been used for a number of internal use cases at Block as well as by the general AI builder ecosystem.
In this episode, we dig into:
Block's history releasing and supporting open source projects, and how that led to the creation of the programs office
How big companies like Block approach open source and come up with ideas for projects like Goose
The Goose project and how it's different from other agent frameworks
Tue. 06/24 – Is Microsoft Struggling To Sell Copilot?
Techmeme Ride Home •
A new Xbox branded Meta Quest. Amazon is expanding same day delivery even more. What does it mean for the AI race if ChatGPT seems to be outcompeting Microsoft’s Copilot offerings in the enterprise space? Why is Wall Street leading the way on AI adoption? And what exactly is Mira Murati’s big new AI startup going to do, exactly?
Sponsors:
- Venice.ai/techmeme and code: techmeme
Links:
- After a year of waiting, Microsoft's Meta Quest 3S "Xbox Edition" is here — our hands-on review of this (very) limited edition partnership (Windows Central)
- Amazon bringing same-day delivery to ‘millions’ of rural customers (The Verge)
- Tesla Robotaxi Incidents Draw Scrutiny From US Safety Agency (Bloomberg)
- Waymo’s robotaxis are now available on the Uber app in Atlanta (The Verge)
- ChatGPT's Enterprise Success Against Copilot Fuels OpenAI and Microsoft's Rivalry (Bloomberg)
- Goldman Sachs launches AI assistant firmwide, memo shows (Reuters)
- Thinking Machines Lab’s $2B Seed Round Is Biggest By A Long Shot (Crunchbase News)
- How Ex-OpenAI CTO Murati’s Startup Plans to Compete With OpenAI and Others (The Information)
See Privacy Policy at https://art19.com/privacy and California Privacy Notice at https://art19.com/privacy#do-not-sell-my-info.
Kotlin Notebook Upgrade: Smoother UI and More Stability
Kotlin by JetBrains •

Building the Internet of Agents with Vijoy Pandey - #737
The TWIML AI Podcast (formerly This Week in Machine Learning & Artificial Intelligence) •

Greg Kamradt: Benchmarking Intelligence | ARC Prize
MLOps.community •

What makes a good AI benchmark? Greg Kamradt joins Demetrios to break it down—from human-easy, AI-hard puzzles to wild new games that test how fast models can truly learn. They talk hidden datasets, compute tradeoffs, and why benchmarks might be our best bet for tracking progress toward AGI. It’s nerdy, strategic, and surprisingly philosophical.
// Bio
Greg has mentored thousands of developers and founders, empowering them to build AI-centric applications.By crafting tutorial-based content, Greg aims to guide everyone from seasoned builders to ambitious indie hackers.Greg partners with companies during their product launches, feature enhancements, and funding rounds. His objective is to cultivate not just awareness, but also a practical understanding of how to optimally utilize a company's tools.He previously led Growth @ Salesforce for Sales & Service Clouds in addition to being early on at Digits, a FinTech Series-C company.
// Related Links
Website: https://gregkamradt.com/
YouTube channel: https://www.youtube.com/@DataIndependent
~~~~~~~~ ✌️Connect With Us ✌️ ~~~~~~~
Catch all episodes, blogs, newsletters, and more: https://go.mlops.community/TYExplore
MLOps Swag/Merch: [https://shop.mlops.community/]
Connect with Demetrios on LinkedIn: /dpbrinkm
Connect with Greg on LinkedIn: /gregkamradt/
Timestamps:
[00:00] Human-Easy, AI-Hard
[05:25] When the Model Shocks Everyone
[06:39] “Let’s Circle Back on That Benchmark…”
[09:50] Want Better AI? Pay the Compute Bill
[14:10] Can We Define Intelligence by How Fast You Learn?
[16:42] Still Waiting on That Algorithmic Breakthrough
[20:00] LangChain Was Just the Beginning
[24:23] Start With Humans, End With AGI
[29:01] What If Reality’s Just... What It Seems?
[32:21] AI Needs Fewer Vibes, More Predictions
[36:02] Defining Intelligence (No Pressure)
[36:41] AI Building AI? Yep, We're Going There
[40:13] Open Source vs. Prize Money Drama
[43:05] Architecting the ARC Challenge
[46:38] Agent 57 and the Atari Gauntlet
Ep. #15, Codename Goose and the Future of AI Agents with Adewale Abati
Open Source Ready •

In episode 15 of Open Source Ready, Brian and John chat with Adewale "Ace" Abati from Block about Codename Goose, an open-source AI agent, and the underlying Model Context Protocol (MCP). They explore how AI agents are revolutionizing developer workflows, the concept of "vibe coding" for rapid prototyping, and the future of AI in productivity and accessibility.
The Blueprint For AI Agents That Work (ft Diamond Bishop)
Tool Use - AI Conversations •

Master the art of building AI agents and powerful AI teammates with Diamond Bishop, Director of Engineering and AI at Datadog. In this deep dive, we explore crucial strategies for creating self-improving agent systems, from establishing robust evaluations (evals) and observability to designing effective human-in-the-loop escape hatches. Learn the secrets to building user trust, deciding between prompt engineering and fine-tuning, and managing data sets for peak performance. Diamond shares his expert insights on architecting agents, using LLM as a judge for quality control, and the future of ambient AI in DevSecOps. If you're looking to build your own AI assistant, this episode provides the essential principles and practical advice you need to get started and create systems that learn and improve over time.
Guest: Diamond Bishop, Director of Engineering and AI at Datadog
Learn more about Bits AI SRE: https://www.datadoghq.com/blog/bits-ai-sre/
Datadog MCP Server for Agents: https://www.datadoghq.com/blog/datadog-remote-mcp-server/
Sign up for A.I. coaching for professionals at: https://www.anetic.co
Get FREE AI tools
pip install tool-use-ai
Connect with us
https://x.com/MikeBirdTech
https://x.com/diamondbishop
00:00:00 - Intro
00:03:55 - When To Use an Agent vs a Script
00:05:44 - How to Architect an AI Agent
00:08:07 - Prompt Engineering vs Fine-Tuning
00:11:29 - Building Your First Eval Suite
00:26:06 - The Unsolved Problem in Agent Building
00:31:10 - The Future of Local AI Models & Privacy
Subscribe for more insights on AI tools, productivity, and agents.
Tool Use is a weekly conversation with AI experts brought to you by Anetic.
Apple in China
ChinaTalk •

Why LLMs Keep Missing This One Thing | Jason Ganz
The AI Native Dev - from Copilot today to AI Native Software Development tomorrow •

Can LLMs replace structured systems to scale enterprises?
Jason Ganz, Senior Manager DX at dbt Labs, joins Simon Maple to unpack why, despite the rapid rise of AI systems, enterprises still rely on structured data for consistency and reliable decision making.
They also discuss:
- the invisible edge cases LLMs can’t see
- difference between software engineering and data engineering in AI
- the mismatch between AI output and business logic
- what the data engineer of the future actually does
AI Native Dev, powered by Tessl and our global dev community, is your go-to podcast for solutions in software development in the age of AI. Tune in as we engage with engineers, founders, and open-source innovators to talk all things AI, security, and development.
Connect with us here:
1. Jason Ganz (LinkedIn)- https://www.linkedin.com/in/jasnonaz/
2. Jason Ganz (X)- https://x.com/jasnonaz
3. dbt Labs- https://www.getdbt.com/
4. dbt Fusion engine- https://www.getdbt.com/product/fusion
5. dbt Community- https://www.getdbt.com/community
6. Simon Maple- https://www.linkedin.com/in/simonmaple/
7. Tessl- https://www.linkedin.com/company/tesslio/
8. AI Native Dev- https://www.linkedin.com/showcase/ai-native-dev/
00:00 Trailer
01:01 Introduction
01:41 dbt Labs
04:39 Data engineers
07:39 LLMs understanding
13:15 AI isn’t as lazy as humans
15:29 Problem: the scaffolding to get data
17:38 Best contextual results
19:40 Dealing with security
25:00 Structured data
27:37 Problems with LLMs and data
29:47 Exact numbers
32:10 Hallucinations
34:28 Human validation
36:20 MCP servers
39:09 UX bottlenecks
42:27 Quality of data
44:00 The future of data engineers
47:02 getdbt.com
48:09 Outro
Join the AI Native Dev Community on Discord: https://tessl.co/4ghikjh
Ask us questions: podcast@tessl.io
CodeRabbit and RAG for Code Review with Harjot Gill
Software Engineering Daily •
One of the most immediate and high-impact applications of LLMs has been in software development. The models can significantly accelerate code writing, but with that increased velocity comes a greater need for thoughtful, scalable approaches to codereview. Integrating AI into the development workflow requires rethinking how to ensure quality,security, and maintainability at scale. CodeRabbit is
The post CodeRabbit and RAG for Code Review with Harjot Gill appeared first on Software Engineering Daily.
Shivay Lamba: How to run secure AI anywhere with WebAssembly
ConTejas Code •

Links
- CodeCrafters (partner): https://tej.as/codecrafters
- WebAssembly on Kubernetes: https://www.cncf.io/blog/2024/03/12/webassembly-on-kubernetes-from-containers-to-wasm-part-01/
- Shivay on X: https://x.com/howdevelop
- Tejas on X: https://x.com/tejaskumar_
Summary
In this podcast episode, Shivay Lamba and I discuss the integration of WebAssembly with AI and machine learning, exploring its implications for developers. We dive into the benefits of running machine learning models in the browser, the significance of edge computing, and the performance advantages of WebAssembly over traditional serverless architectures. The conversation also touches on emerging hardware solutions for AI inference and the importance of accessibility in software development. Shivay shares insights on how developers can leverage these technologies to build efficient and privacy-focused applications.
Chapters
00:00 Shivay Lamba
03:02 Introduction and Background
06:02 WebAssembly and AI Integration
08:47 Machine Learning on the Edge
11:43 Privacy and Data Security in AI
15:00 Quantization and Model Optimization
17:52 Tools for Running AI Models in the Browser
32:13 Understanding TensorFlow.js and Its Architecture
37:58 Custom Operations and Model Compatibility
41:56 Overcoming Limitations in JavaScript ML Workloads
46:00 Demos and Practical Applications of TensorFlow.js
54:22 Server-Side AI Inference with WebAssembly
01:02:42 Building AI Inference APIs with WebAssembly
01:04:39 WebAssembly and Machine Learning Inference
01:10:56 Summarizing the Benefits of WebAssembly for Developers
01:15:43 Learning Curve for Developers in Machine Learning
01:21:10 Hardware Considerations for WebAssembly and AI
01:27:35 Comparing Inference Speeds of AI Models
Hosted on Acast. See acast.com/privacy for more information.
E176: Why All AI Agents Will Need Cloud Sandboxes
Open Source Startup Podcast •

Vasek Mlejnsky is Co-Founder & CEO of E2B, the open-source runtime for executing AI-generated code in secure cloud sandboxes. Essentially, they give AI agents cloud computers.
Their open source repos, particularly e2b which has 9K GitHub stars, have been widely adopted to help securely run AI-generated code.
E2B has raised $12M from investors including Decibel and Sunflower.
In this episode, we dig into:
Why agents need a sandbox
Building a new category of infra tooling, much like LaunchDarkly
Some of their viral content moments - including Greg Brockman sharing their videos
Figuring out the right commercial offering
Why they don't agree with pricing per token
Why moving from Prague to the Bay Area felt essential for them as founders
Ep. #11, Unpacking MCP with Steve Manuel
Open Source Ready •
In episode 11 of Open Source Ready, Brian Douglas and John McBride sit down with AI expert Steve Manuel to explore the Model Context Protocol (MCP)—a framework that enhances how models interact with their environments. They break down why context-awareness is crucial for machine learning and how MCP is transforming open source AI.
899: Landing $200k+ AI Roles: Real Cases from the SuperDataScience Community, with Kirill Eremenko
Super Data Science: ML & AI Podcast with Jon Krohn •

Baby Registries, Cold Showers, and Launching opencode
How About Tomorrow? •

Links:
- Dax's tweet about opencode rewrite
- opencode.ai
- Intro | opencode
- GitHub - sst/opencode: AI coding agent, built for the terminal.
- Andrej Karpathy: Software Is Changing (Again) - YouTube
- Models.dev — An open-source database of AI models
Sponsor: Terminal now offers a monthly box called Cron.
Want to carry on the conversation? Join us in Discord. Or send us an email at sliceoffalittlepieceofbacon@tomorrow.fm.
Topics:
- (00:00) - A Canadian standoff
- (00:29) - Who's the resident nice guy around here?
- (02:27) - Finding the Apple of carseats and baby strollers
- (05:39) - Transitioning from walking to running
- (08:03) - Sleeping struggles
- (11:21) - Launching Opencode
- (16:48) - Is starting a podcast the key to working well together as programmers? 4 out of 5 podcast editors say yes
- (22:46) - Figuring out what to work on next in open source software
- (32:29) - Dax is still living in oblivious bliss from Twitter
- (33:45) - Andrej Karpathy on how Software Is Changing
- (35:53) - Dax tries vibe coding
- (46:30) - How much of a bet are we placing on the terminal?
- (48:17) - Writing code for Frank
A Blast From Computing Past
The Aboard Podcast •

Same as it ever was: On this week’s podcast, Paul and Rich take a spin through a 1980 issue of Omni magazine, comparing how computers were being discussed back then with how AI is talked about today. Featuring an essay by Frank Herbert (yes, of Dune), IBM’s early-80s consumer pitch, and a meditation on the question: What does “new technology” even mean?
(Preview) Justice for Software Engineers, The Various Futures of Vibe Coding, Questions at xAI and Progress for Tesla
Sharp Tech with Ben Thompson •
Rippling spy says men have been following him, and his wife is afraid
TechCrunch Industry News •
Leak reveals Grok might soon edit your spreadsheets
TechCrunch Daily Crunch •
VanMoof is back with a new custom e-bike and rebooted repair network
TechCrunch Startup News •
Ep. #16, Building Tools That Spark Joy with Mitchell Hashimoto
Open Source Ready •
On episode 16 of Open Source Ready, Brian and John sit down with Mitchell Hashimoto, founder of HashiCorp, to discuss his journey after leaving the company and his latest passion project, the open source terminal emulator Ghostty. Mitchell shares the accidental origins of Ghostty, his pragmatic approach to technology, and his thoughts on the current state of open source business models. Lastly, they explore the complexities of AI development and the trade-offs of foundation governance.
#437 Python Language Summit 2025 Highlights
Python Bytes •

- * The Python Language Summit 2025*
- Fixing Python Properties
- * complexipy*
- * juvio*
- Extras
- Joke
About the show
Sponsored by Posit: pythonbytes.fm/connect
Connect with the hosts
- Michael: @mkennedy@fosstodon.org / @mkennedy.codes (bsky)
- Brian: @brianokken@fosstodon.org / @brianokken.bsky.social
- Show: @pythonbytes@fosstodon.org / @pythonbytes.fm (bsky)
Join us on YouTube at pythonbytes.fm/live to be part of the audience. Usually Monday at 10am PT. Older video versions available there too.
Finally, if you want an artisanal, hand-crafted digest of every week of the show notes in email form? Add your name and email to our friends of the show list, we'll never share it.
Michael #1: The Python Language Summit 2025
- Write up by Seth Michael Larson
- How can we make breaking changes less painful?: talk by Itamar Oren
- An Uncontentious Talk about Contention: talk by Mark Shannon
- State of Free-Threaded Python: talk by Matt Page
- Fearless Concurrency: talk by Matthew Parkinson, Tobias Wrigstad, and Fridtjof Stoldt
- Challenges of the Steering Council: talk by Eric Snow
- Updates from the Python Docs Editorial Board: talk by Mariatta
- PEP 772 - Packaging Governance Process: talk by Barry Warsaw and Pradyun Gedam
- Python on Mobile - Next Steps: talk by Russell Keith-Magee
- What do Python core developers want from Rust?: talk by David Hewitt
- Upstreaming the Pyodide JS FFI: talk by Hood Chatham
- Lightning Talks: talks by Martin DeMello, Mark Shannon, Noah Kim, Gregory Smith, Guido van Rossum, Pablo Galindo Salgado, and Lysandros Nikolaou
Brian #2: Fixing Python Properties
- Will McGugan
- “Python properties work well with type checkers such Mypy and friends. … The type of your property is taken from the getter only. Even if your setter accepts different types, the type checker will complain on assignment.”
- Will describes a way to get around this and make type checkers happy.
- He replaces
@propertywith a descriptor. It’s a cool technique. - I also like the way Will is allowing different ways to use a property such that it’s more convenient for the user. This is a cool deverloper usability trick.
Brian #3: complexipy
- Calculates the cognitive complexity of Python files, written in Rust.
- Based on the cognitive complexity measurement described in a white paper by Sonar
- Cognitive complexity builds on the idea of cyclomatic complexity.
- Cyclomatic complexity was intended to measure the “testability and maintainability” of the control flow of a module. Sonar argues that it’s fine for testability, but doesn’t do well with measuring the “maintainability” part. So they came up with a new measure.
- Cognitive complexity is intended to reflects the relative difficulty of understanding, and therefore of maintaining methods, classes, and applications.
- complexipy essentially does that, but also has a really nice color output.
- Note: at the very least, you should be using “cyclomatic complexity”
- try with
ruff check --select C901
- try with
- But also try complexipy.
- Great for understanding which functions might be ripe for refactoring, adding more documentation, surrounding with more tests, etc.
Michael #4: juvio
- uv kernel for Jupyter
- ⚙️ Automatic Environment Setup: When the notebook is opened, Juvio installs the dependencies automatically in an ephemeral virtual environment (using
uv), ensuring that the notebook runs with the correct versions of the packages and Python - 📁 Git-Friendly Format: Notebooks are converted on the fly to a script-style format using
# %%markers, making diffs and version control painless - Why Use Juvio?
- No additional lock or requirements files are needed
- Guaranteed reproducibility
- Cleaner Git diffs
- Powered By
uv– ultra-fast Python package managementPEP 723– Python inline dependency standards
Extras
Brian:
- Test & Code in slow mode currently. But will be back with some awesome interviews.
Joke: The 0.1x Engineer
- via Balázs
- Also
The State of Authentication: The Future is BUNDLED!
Modern Web •

On this episode of the Modern Web Podcast, Rob Ocel and Danny Thompson talk with Brian Morrison, Senior Developer Educator at Clerk. They cover the state of authentication today, what makes Clerk stand out for small teams and indie builders, and how thoughtful developer experience design can make or break adoption.Brian shares why bundling tools like auth, billing, and user management is becoming more common, how Clerk handles real-world concerns like bot protection and social login, and why starting with a great developer experience matters more than ever.The conversation also explores the role of AI in software development and content creation, where it helps, where it hurts, and how to use it responsibly without losing quality or trust.Keypoints for this Episode:
- Modern auth is about experience, not just security. Clerk simplifies user management, social login, bot protection, and subscription billing with developer-friendly APIs and polished default UIs.
- Bundled platforms are making a comeback. Developers are shifting from handpicking tools to using tightly integrated services that reduce setup time and complexity.
- Developer education needs more care and creativity. Brian emphasizes the importance of visual storytelling, thoughtful structure, and anticipating confusion to help devs learn faster and retain more.
- AI is a productivity multiplier, not a replacement. The group discusses how AI can accelerate development and content creation when used with oversight, but warn against using it to blindly build entire apps.
Follow Brian Morrison on Social MediaTwitter: https://x.com/brianmmdevLinkedin: https://www.linkedin.com/in/brianmmdev/Sponsored by This Dot: thisdotlabs.com
Unlocking AI Potential with AMD’s ROCm Stack
AI Engineering Podcast •
In this episode of the AI Engineering podcast Anush Elangovan, VP of AI software at AMD, discusses the strategic integration of software and hardware at AMD. He emphasizes the open-source nature of their software, fostering innovation and collaboration in the AI ecosystem, and highlights AMD's performance and capability advantages over competitors like NVIDIA. Anush addresses challenges and opportunities in AI development, including quantization, model efficiency, and future deployment across various platforms, while also stressing the importance of open standards and flexible solutions that support efficient CPU-GPU communication and diverse AI workloads.
Announcements
- Hello and welcome to the AI Engineering Podcast, your guide to the fast-moving world of building scalable and maintainable AI systems
- Your host is Tobias Macey and today I'm interviewing Anush Elangovan about AMD's work to expand the playing field for AI training and inference
- Introduction
- How did you get involved in machine learning?
- Can you describe what your work at AMD is focused on?
- A lot of the current attention on hardware for AI training and inference is focused on the raw GPU hardware. What is the role of the software stack in enabling and differentiating that underlying compute?
- CUDA has gained a significant amount of attention and adoption in the numeric computation space (AI, ML, scientific computing, etc.). What are the elements of platform risk associated with relying on CUDA as a developer or organization?
- The ROCm stack is the key element in AMD's AI and HPC strategy. What are the elements that comprise that ecosystem?
- What are the incentives for anyone outside of AMD to contribute to the ROCm project?
- How would you characterize the current competitive landscape for AMD across the AI/ML lifecycle stages? (pre-training, post-training, inference, fine-tuning)
- For teams who are focused on inference compute for model serving, what do they need to know/care about in regards to AMD hardware and the ROCm stack?
- What are the most interesting, innovative, or unexpected ways that you have seen AMD/ROCm used?
- What are the most interesting, unexpected, or challenging lessons that you have learned while working on AMD's AI software ecosystem?
- When is AMD/ROCm the wrong choice?
- What do you have planned for the future of ROCm?
Parting Question
- From your perspective, what are the biggest gaps in tooling, technology, or training for AI systems today?
- Thank you for listening! Don't forget to check out our other shows. The Data Engineering Podcast covers the latest on modern data management. Podcast.__init__ covers the Python language, its community, and the innovative ways it is being used.
- Visit the site to subscribe to the show, sign up for the mailing list, and read the show notes.
- If you've learned something or tried out a project from the show then tell us about it! Email hosts@aiengineeringpodcast.com with your story.
- To help other people find the show please leave a review on iTunes and tell your friends and co-workers.
- ImageNet
- AMD
- ROCm
- CUDA
- HuggingFace
- Llama 3
- Llama 4
- Qwen
- DeepSeek R1
- MI300X
- Nokia Symbian
- UALink Standard
- Quantization
- HIPIFY
- ROCm Triton
- AMD Strix Halo
- AMD Epyc
- Liquid Networks
- MAMBA Architecture
- Transformer Architecture
- NPU == Neural Processing Unit
- llama.cpp
- Ollama
- Perplexity Score
- NUMA == Non-Uniform Memory Access
- vLLM
- SGLang
Mon. 06/23 – Tesla Launches Its Robotaxi
Techmeme Ride Home •
Tesla launches its robotaxi service in Austin. Apple is negotiating desperately to avoid an EU fine coming as soon as this week. Also, why doesn’t Apple do some acquihires to get back in the AI game? Maybe Perplexity would be attractive? The Music industry gathers tools to detect AI. And is there a global divide growing when it comes to AI access?
Sponsors:
Links:
- Tesla launches robotaxi service in Austin (Financial Times)
- Jony Ive Deal Removed From OpenAI Site Over Trademark Suit (Bloomberg)
- Apple locked in last-minute App Store negotiations to avoid Brussels fines (Financial Times)
- Apple Will Need to Leave Its M&A Comfort Zone to Succeed in AI (Bloomberg)
- Apple Executives Have Held Internal Talks About Buying AI Startup Perplexity (Bloomberg)
- The music industry is building the tech to hunt down AI songs (The Verge)
- The Global A.I. Divide (NYTimes)
See Privacy Policy at https://art19.com/privacy and California Privacy Notice at https://art19.com/privacy#do-not-sell-my-info.
The Robinhood founder who might just revolutionize energy, if he succeeds
TechCrunch Industry News •
Stripe’s former growth lead helps African diaspora invest in startups, real estate
TechCrunch Startup News •
AI Testing and Evaluation: Learnings from Science and Industry
Microsoft Research Podcast •

In the introductory episode of this new series, host Kathleen Sullivan and Senior Director Amanda Craig Deckard explore Microsoftâs efforts to draw on the experience of other domains to help advance the role of AI testing and evaluation as a governance tool.
Everything you need to run Mission Critical Inference (ft. DeepSeek v3 + SGLang)
Latent Space: The AI Engineer Podcast •
Sponsorships and applications for the AI Engineer Summit in NYC are live! (Speaker CFPs have closed) If you are building AI agents or leading teams of AI Engineers, this will be the single highest-signal conference of the year for you.
Right after Christmas, the Chinese Whale Bros ended 2024 by dropping the last big model launch of the year: DeepSeek v3. Right now on LM Arena, DeepSeek v3 has a score of 1319, right under the full o1 model, Gemini 2, and 4o latest. This makes it the best open weights model in the world in January 2025.
There has been a big recent trend in Chinese labs releasing very large open weights models, with TenCent releasing Hunyuan-Large in November and Hailuo releasing MiniMax-Text this week, both over 400B in size. However these extra-large language models are very difficult to serve.
Baseten was the first of the Inference neocloud startups to get DeepSeek V3 online, because of their H200 clusters, their close collaboration with the DeepSeek team and early support of SGLang, a relatively new VLLM alternative that is also used at frontier labs like X.ai. Each H200 has 141 GB of VRAM with 4.8 TB per second of bandwidth, meaning that you can use 8 H200's in a node to inference DeepSeek v3 in FP8, taking into account KV Cache needs.
We have been close to Baseten since Sarah Guo introduced Amir Haghighat to swyx, and they supported the very first Latent Space Demo Day in San Francisco, which was effectively the trial run for swyx and Alessio to work together!
Since then, Philip Kiely also led a well attended workshop on TensorRT LLM at the 2024 World's Fair.
We worked with him to get two of their best representatives, Amir and Lead Model Performance Engineer Yineng Zhang, to discuss DeepSeek, SGLang, and everything they have learned running Mission Critical Inference workloads at scale for some of the largest AI products in the world.
The Three Pillars of Mission Critical Inference
We initially planned to focus the conversation on SGLang, but Amir and Yineng were quick to correct us that the choice of inference framework is only the simplest, first choice of 3 things you need for production inference at scale:
“I think it takes three things, and each of them individually is necessary but not sufficient:
* Performance at the model level: how fast are you running this one model running on a single GPU, let's say. The framework that you use there can, can matter. The techniques that you use there can matter. The MLA technique, for example, that Yineng mentioned, or the CUDA kernels that are being used. But there's also techniques being used at a higher level, things like speculative decoding with draft models or with Medusa heads. And these are implemented in the different frameworks, or you can even implement it yourself, but they're not necessarily tied to a single framework. But using speculative decoding gets you massive upside when it comes to being able to handle high throughput. But that's not enough. Invariably, that one model running on a single GPU, let's say, is going to get too much traffic that it cannot handle.
* Horizontal scaling at the cluster/region level: And at that point, you need to horizontally scale it. That's not an ML problem. That's not a PyTorch problem. That's an infrastructure problem. How quickly do you go from, a single replica of that model to 5, to 10, to 100. And so that's the second, that's the second pillar that is necessary for running these machine critical inference workloads.
And what does it take to do that? It takes, some people are like, Oh, You just need Kubernetes and Kubernetes has an autoscaler and that just works. That doesn't work for, for these kinds of mission critical inference workloads. And you end up catching yourself wanting to bit by bit to rebuild those infrastructure pieces from scratch. This has been our experience.
* And then going even a layer beyond that, Kubernetes runs in a single. cluster. It's a single cluster. It's a single region tied to a single region. And when it comes to inference workloads and needing GPUs more and more, you know, we're seeing this that you cannot meet the demand inside of a single region. A single cloud's a single region. In other words, a single model might want to horizontally scale up to 200 replicas, each of which is, let's say, 2H100s or 4H100s or even a full node, you run into limits of the capacity inside of that one region. And what we had to build to get around that was the ability to have a single model have replicas across different regions. So, you know, there are models on Baseten today that have 50 replicas in GCP East and, 80 replicas in AWS West and Oracle in London, etc.
* Developer experience for Compound AI Systems: The final one is wrapping the power of the first two pillars in a very good developer experience to be able to afford certain workflows like the ones that I mentioned, around multi step, multi model inference workloads, because more and more we're seeing that the market is moving towards those that the needs are generally in these sort of more complex workflows.
We think they said it very well.
Show Notes
* Amir Haghighat, Co-Founder, Baseten
* Yineng Zhang, Lead Software Engineer, Model Performance, Baseten
Full YouTube Episode
Please like and subscribe!
Timestamps
* 00:00 Introduction and Latest AI Model Launch
* 00:11 DeepSeek v3: Specifications and Achievements
* 03:10 Latent Space Podcast: Special Guests Introduction
* 04:12 DeepSeek v3: Technical Insights
* 11:14 Quantization and Model Performance
* 16:19 MOE Models: Trends and Challenges
* 18:53 Baseten's Inference Service and Pricing
* 31:13 Optimization for DeepSeek
* 31:45 Three Pillars of Mission Critical Inference Workloads
* 32:39 Scaling Beyond Single GPU
* 33:09 Challenges with Kubernetes and Infrastructure
* 33:40 Multi-Region Scaling Solutions
* 35:34 SG Lang: A New Framework
* 38:52 Key Techniques Behind SG Lang
* 48:27 Speculative Decoding and Performance
* 49:54 Future of Fine-Tuning and RLHF
* 01:00:28 Baseten's V3 and Industry Trends
Baseten’s previous TensorRT LLM workshop:
Get full access to Latent.Space at www.latent.space/subscribe
#111 Wasm & MCP with Steve Manuel
Happy Path Programming •

We chat with Steve Manuel (of dylibso.com and mcp.run) about LLM "plugins" with Wasm & MCP (Model Context Protocol).
Discuss this episode: discord.gg/XVKD2uPKyF
Jacob Leverich chats Observe and the Future of Observability
The MonkCast •
In this RedMonk conversation, Jacob Leverich, Co-Founder at Observe, Inc., discusses the evolution of the observability market, focusing on the founding of Observe, and the architectural decisions that shaped its development, with RedMonk's James Governor. They explore the transition from on-premises to cloud-based solutions, the challenges of data collection and interpretation, and the importance of user context in troubleshooting. The discussion also covers the impact of OpenTelemetry on the industry and the ongoing challenges of cost management in observability solutions. They explore emerging trends in data management, including the commoditization of data storage and the impact of AI on observability practices.
The Three Ps: Understanding Product, Project, and Program Management
Fallthrough •
Building software is difficult and rarely can software engineers do it alone. In this episode, Kris is joined by Ian, Matthew, and Angelica to talk managing software projects and what three often used but rarely defined roles actually mean: project manager, product manager, and program manager. The panel also discusses how these roles interact with engineering managers, what they think these roles actually do, and whether product managers should actually exist.
For our supporters, this episode contains an extended discussion including a discussion on whether you should trust a new company you join, how to build trust, and what metrics we should measure for project success. Get access by signing up at https://fallthrough.fm/subscribe.
Thanks for tuning in and happy listening!
Table of Contents:
- Prologue (03:28)
- Chapter 1: Product? Project? Program? (05:18)
- Chapter 2: PMs and Software Engineers (13:56)
- Chapter 3: Splitting Roles (44:49)
- Chapter 4: Building Trust [Supporter Only] (53:34)
- Chapter 5: Metrics [Supporter Only] (54:13)
- Chapter 6: Should Product Managers Exist? (55:25)
- Appendix UNPOP: Unpopular Opinions (01:06:37)
- Epilogue (01:11:56)
Hosts
- Kris Brandow - Host
- Ian Wester-Lopshire - Host
- Matthew Sanabria - Host
- Angelica Hill - Producer
Socials:
- (03:28) - Prologue
- (05:18) - Chapter 1: Product? Project? Program?
- (13:56) - Chapter 2: PMs and Software Engineers
- (44:49) - Chapter 3: Splitting Roles
- (53:34) - Chapter 4: Building Trust [Supporter Only]
- (54:13) - Chapter 5: Metrics [Supporter Only]
- (55:25) - Chapter 6: Should Product Managers Exist?
- (01:06:37) - Appendix UNPOP: Unpopular Opinions
- (01:11:56) - Epilogue
Developing a Mental Model for AI - Thinking Like a Large Language Model by Mukund Sundararajan
Book Overflow •

In this episode of Book Overflow, Carter and Nathan discuss Thinking Like a Large Language Model by Mukund Sundararajan. Join them as they discuss the different mental models for working with AI, the art of prompt engineering, and some exciting developments in Carter's career!
-- Books Mentioned in this Episode --
Note: As an Amazon Associate, we earn from qualifying purchases.
----------------------------------------------------------
Thinking Like a Large Language Model by Mukund Sundararajan
https://amzn.to/466v89G (paid link)
----------------
Spotify: https://open.spotify.com/show/5kj6DLCEWR5nHShlSYJI5L
Apple Podcasts: https://podcasts.apple.com/us/podcast/book-overflow/id1745257325
X: https://x.com/bookoverflowpod
Carter on X: https://x.com/cartermorgan
Nathan's Functionally Imperative: www.functionallyimperative.com
----------------
Book Overflow is a podcast for software engineers, by software engineers dedicated to improving our craft by reading the best technical books in the world. Join Carter Morgan and Nathan Toups as they read and discuss a new technical book each week!
The full book schedule and links to every major podcast player can be found at https://www.bookoverflow.io
620: Brent Loves Building Things
LINUX Unplugged •

Off-the-shelf didn't cut it, so we built what we needed using open hardware and open source.
Sponsored By:
- Tailscale: Tailscale is a programmable networking software that is private and secure by default - get it free on up to 100 devices!
- 1Password Extended Access Management: 1Password Extended Access Management is a device trust solution for companies with Okta, and they ensure that if a device isn't trusted and secure, it can't log into your cloud apps.
- Unraid: A powerful, easy operating system for servers and storage. Maximize your hardware with unmatched flexibility.
Links:
- 💥 Gets Sats Quick and Easy with Strike
- 📻 LINUX Unplugged on Fountain.FM
- Castamatic
- Castamatic 11 - with live shows and Podping — With this release, you can now listen to live podcast episodes directly in the app and get instant notifications as soon as a new episode—live or recorded—is available.
- ESP8266 NodeMCU
- DHT22/AM2302 Digital Temperature and Humidity Sensor Module
- 5V One Channel Relay Module Relay Switch with OPTO Isolation High Low Level Trigger
- Marine Boat 3" in-Line Bilge Air Blower DC 12V 130 CFM
- Wolfwhoop PW-D Control Buck Converter 6-24V to 5V 1.5A Step-Down Regulator Module Power Inverter Volt Stabilizer
- TICONN Waterproof Electrical Junction Box
- BOJACK 3 Values 130 Pcs Solderless Breadboard
- ESPHome Web - web.esphome.io — Allows you to prepare your device for first use, install new versions and check the device logs directly from your browser.
- PlatformIO - Your Gateway to Embedded Software Development Excellence
- buildFHSEnv - nixpkgs — Provides a way to build and run FHS-compatible lightweight sandboxes.
- ESPHome NixOS module: Failure to compile firmware because of DynamicUsers
- Pick: High Tide — Third party unofficial TIDAL music client. Listen to your favorite music from your desktop or mobile Linux device at the highest quality.
- Pick: Junction — Junction pops up automatically when you open a file or link in another app.
- Junction on Flathub
Building the Middle Tier and Doing Software Migrations: A Conversation with Rashmi Venugopal
The InfoQ Podcast •

913: NEWS: Remix drops React, Safari 26 CSS + mega fast Vite and TypeSCript
Syntax - Tasty Web Development Treats •

#307 Human Guardrails in Generative AI with Wendy Gonzalez & Duncan Curtis, CEO & SVP of Gen AI at Sama
DataFramed •

The line between generic AI capabilities and truly transformative business applications often comes down to one thing: your data. While foundation models provide impressive general intelligence, they lack the specialized knowledge needed for domain-specific tasks that drive real business value. But how do you effectively bridge this gap? What's the difference between simply fine-tuning models versus using techniques like retrieval-augmented generation? And with constantly evolving models and technologies, how do you build systems that remain adaptable while still delivering consistent results? Whether you're in retail, healthcare, or transportation, understanding how to properly enrich, annotate, and leverage your proprietary data could be the difference between an AI project that fails and one that fundamentally transforms your business.
Wendy Gonzalez is the CEO — and former COO — of Sama, a company leading the way in ethical AI by delivering accurate, human-annotated data while advancing economic opportunity in underserved communities. She joined Sama in 2015 and has been central to scaling both its global operations and its mission-driven business model, which has helped over 65,000 people lift themselves out of poverty through dignified digital work. With over 20 years of experience in the tech and data space, Wendy’s held leadership roles at EY, Capgemini, and Cycle30, where she built and managed high-performing teams across complex, global environments. Her leadership style blends operational excellence with deep purpose — ensuring that innovation doesn’t come at the expense of integrity. Wendy is also a vocal advocate for inclusive AI and sustainable impact, regularly speaking on how companies can balance cutting-edge technology with real-world responsibility.
Duncan Curtis is the Senior Vice President of Generative AI at Sama, where he leads the development of AI-powered tools that are shaping the future of data annotation. With a background in product leadership and machine learning, Duncan has spent his career building scalable systems that bridge cutting-edge technology with real-world impact. Before joining Sama, he led teams at companies like Google, where he worked on large-scale personalization systems, and contributed to AI product strategy across multiple sectors. At Sama, he's focused on harnessing the power of generative AI to improve quality, speed, and efficiency — all while keeping human oversight and ethical practices at the core. Duncan brings a unique perspective to the AI space: one that’s grounded in technical expertise, but always oriented toward practical solutions and responsible innovation.
In the episode, Richie, Wendy, and Duncan explore the importance of using specialized data with large language models, the role of data enrichment in improving AI accuracy, the balance between automation and human oversight, the significance of responsible AI practices, and much more.
Links Mentioned in the Show:
- Sama
- Connect with Wendy
- Connect with Duncan
- Course: Generative AI Concepts
- Related Episode: Creating High Quality AI Applications with Theresa Parker & Sudhi Balan, Rocket Software
- Register for RADAR AI
New to DataCamp?
- Learn on the go...
Jonas Sølvsteen/Henry Rodman: eoAPI
Geomob •

In this episode of the Geomob podcast, Alastair is joined by guests Henry Rodman and Jonas Sølvsteen to discuss the EO API, a new initiative from Development Seed aimed at improving access to geospatial data. They cover their backgrounds in geospatial technology before turning to the API, focusing on how it works and its intended purpose. They delve into the STAC specification, its importance for data cataloging, and the target audience for EO API. The conversation also covers deployment challenges, user experience, and the importance of community engagement in the development of EO API.
Show notes on the Geomob website, where you can also learn more about Geomob events and sign up for our monthly newsletter.
Voi CEO says he’s open to acquiring Bolt’s micromobility business
TechCrunch Industry News •
One UI Gets Fixed, Another Falls
AWS Morning Brief •

AWS Morning Brief for the week of June 23rd, 2025, with Corey Quinn.
Links:
- AWS IAM now enforces MFA for root users across all account types
- AWS expands resource control policies (RCPs) support to two additional services
- One Year EC2 Instance Savings Plans are now available for P5 and P5en instances
- AWS Certificate Manager introduces exportable public SSL/TLS certificates to use anywhere
- Verify internal access to critical AWS resources with new IAM Access Analyzer capabilities
- Introducing AWS CDK Community Meetings
- Rapid monitoring of Amazon S3 bucket policy changes in AWS environments
- 1Password’s New Secrets Syncing Integration With AWS | 1Password
Midjourney launches its first AI video generation model, V1
TechCrunch Startup News •
S04E04 - Better survey design with AI - with Kirsten Hill
Half Stack Data Science •

In this episode, we spoke to Kirsten Hill.
Dr Kirsten Hill is a researcher, writer, and the founder of bisque — a survey platform that actually cares if you get good data. She has a Ph.D. from the University of Pennsylvania, has led research for the Bill & Melinda Gates Foundation, and has worked with over 100 mission-driven teams on measurement & evaluation. This past year, she authored her first book, Ask Better Questions, a top release on survey design — and realized that writing the book wasn’t enough. If she really wanted to change how people do research, she had to build the tools that would make it easier to do it right. With real-time AI feedback, intuitive design, and built-in best practices, bisque makes it easy to create surveys that get you the answers you actually need.
We spoke to Kirsten about how and why surveys are often bad, why she believes the major survey platforms aren't fit for purpose, why she's building her own survey platform "bisque", how she's using Large Language Models to develop a working prototype, and what advice she has for other non-programmers who want to build things with AI.
You can find her on:
- LinkedIn @kirstenleehill
- TikTok @kirstenleehill
- Substack kirstenleehill.substack.com
---
David’s book, The Well-Grounded Data Analyst is out! https://www.manning.com/books/the-well-grounded-data-analyst
If you want to find out more, we have a whole episode about it: https://open.spotify.com/episode/5D0iDtQRh3tWiIhokrjz3x?si=AiX6YyRET16lnzXDlvdcfw
MCP Co-Creator on the Next Wave of LLM Innovation
AI + a16z •

In this episode of AI + a16z, Anthropic's David Soria Parra — who created MCP (Model Context Protocol) along with Justin Spahr-Summers — sits down with a16z's Yoko Li to discuss the project's inception, exciting use cases for connecting LLMs to external sources, and what's coming next for the project. If you're unfamiliar with the wildly popular MCP project, this edited passage from their discussion is a great starting point to learn:
David: "MCP tries to enable building AI applications in such a way that they can be extended by everyone else that is not part of the original development team through these MCP servers, and really bring the workflows you care about, the things you want to do, to these AI applications. It's a protocol that just defines how whatever you are building as a developer for that integration piece, and that AI application, talk to each other.
"It's a very boring specification, but what it enables is hopefully ... something that looks like the current API ecosystem, but for LLM interactions."
Yoko: "I really love the analogy with the API ecosystem, because they give people a mental model of how the ecosystem evolves ... Before, you may have needed a different spec to query Salesforce versus query HubSpot. Now you can use similarly defined API schema to do that.
"And then when I saw MCP earlier in the year, it was very interesting in that it almost felt like a standard interface for the agent to interface with LLMs. It's like, 'What are the set of things that the agent wants to execute on that it has never seen before? What kind of context does it need to make these things happen?' When I tried it out, it was just super powerful and I no longer have to build one tool per client. I now can build just one MCP server, for example, for sending emails, and I use it for everything on Cursor, on Claude Desktop, on Goose."
Learn more:
A Deep Dive Into MCP and the Future of AI Tooling
Benchmarking AI Agents on Full-Stack Coding
Agent Experience: Building an Open Web for the AI Era
Follow everyone on X:
Check out everything a16z is doing with artificial intelligence here, including articles, projects, and more podcasts.